kaggle 圧力コンペ 振り返り
はじめましての人ははじめまして.普段sqrt4kaidoという名前でkaggleのコンペなどに参加しています.
本記事では,先日まで行われていたGoogle Brain - Ventilator Pressure Prediction(通称: 圧力コンペ)の振り返りを行いたいと思います.
今回はちょっと趣向を変えて,概要,反省を折り込みながらのコンペ期間の流れ,そして結果という順で記載しようと思います.
コンペ概要
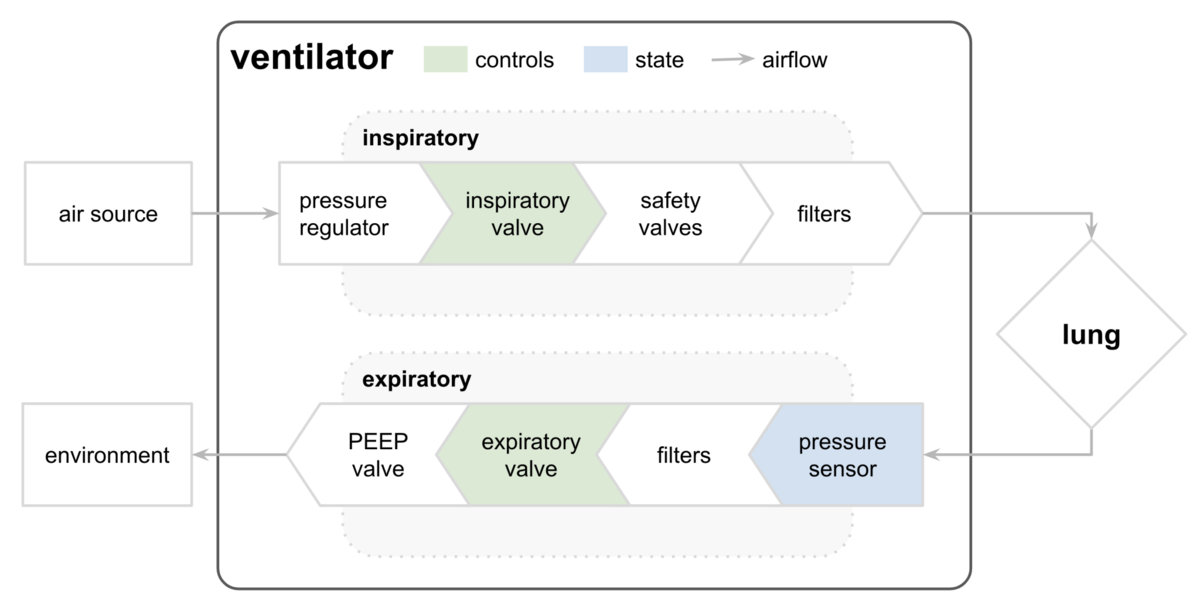
人工呼吸器のシミュレーションとして,ある時刻における肺内の圧力を計算するコンペです.
人工呼吸器は吸気フェーズと呼気フェーズとに分かれており,弁の開き具合や肺の硬さなどの条件により,肺内の圧力が変わってきます.
評価指標は単純なMAEですが,吸気段階のみが評価に使われます.
データ
データは以下のカラムが用意されたテーブルデータでした.カラムの数としては少なく,また時系列性を持っていました.
- time_step…データ取得時間です.
- u_in…吸気電磁弁の制御入力.これは空気を肺へ送る弁の開き具合に相当する量で,0~100の範囲で表されます.
- u_out…呼気を司る弁の値で,0で閉まっている状態,1で開いている状態を表しています.今回のコンペでは,u_out=0の際の圧力が評価対象です.
- R…RはResistanceの略で,肺への空気の入れにくさを表しています(肺へ通ずるストローの太さのイメージ).本コンペでのRは5, 20, 50の3種類であり,50が一番抵抗が高いです.
- C…CはComplianceの略で,肺自体の硬さのような指標です.この数値が高いほど,肺は膨らみやすいです.本コンペでのCは10, 20, 50の3種類です.
- pressure…今回予測するターゲットです.time_stamp時点での気道内圧(cmH2O)です.測定機器の分解能から,測定値は完全な連続値ではなく,950種類の離散的な値となっていました.
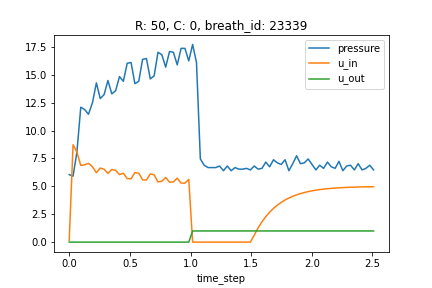
コンペ期間中の流れ
前半
今回は,かなり初期段階からチームを組んで戦いました.
始めはpytorchを用いた回帰予測タスクとして取り組んでいましたが,他にも悩まれていた方が多くいらっしゃったように,pytorchで中々kerasと同程度の性能が出ませんでした.
kerasとpytorchのLSTMにおける初期化の違い等が話題になっており,自分もなかなかkerasの公開ノートブックのスコアを越せず,チューニングにかなり時間をかけてしまいました.
中盤
中盤は,回帰ではなく950クラスのクラス分類タスクとして解く公開ノートブックを試したところ伸びしろがありそう&早く収束しそうだったため,
回帰はチームメンバーに任せて,私はクラス分類モデルを深堀していくことにしました.
中盤でスコア上昇に寄与した要因はだいたい以下のとおりです.
- 加重平均での予測に変更
- todaさんのカスタムloss + 加重平均のMAE loss
- u_inのsqrt
80epochでまあまあの精度が出せるモデルを作ることが出来たので,実験をスピードアップして行うことが出来ていました.(チューニングも引き続き行っていました.)
気づいたこととして,R=50のスコアが悪く,分析してみると細かい動きは当てれているものの,平行に大きくずれるbreath_idがいくつか見られることがありました.
圧力はうまく可視化をすると隠れた何パターンかの設定値が見えてきており,おそらくその予測を間違っているようでした.
と,ここまではよかったのですが,ではこれをどう補正するかがなかなか思いつかず,苦戦しました.おそらくクラスタリングやknnを用いた特徴が効くのではないかと思いましたが,うまく特徴化することが出来ませんでした…
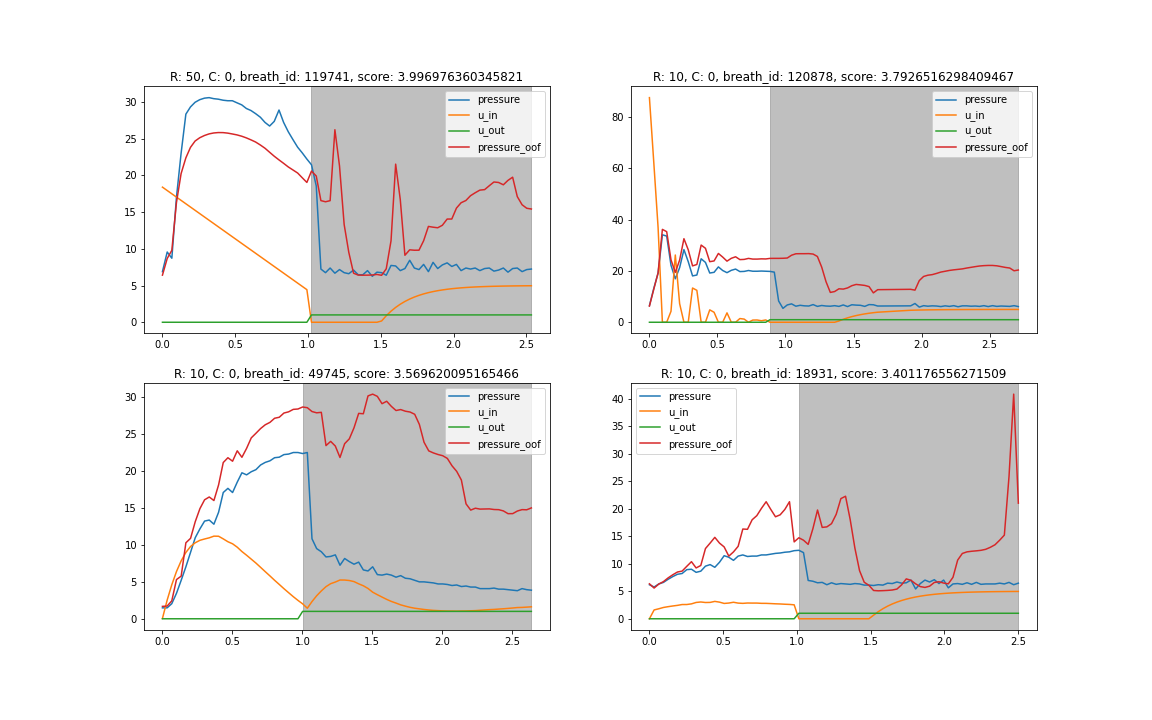
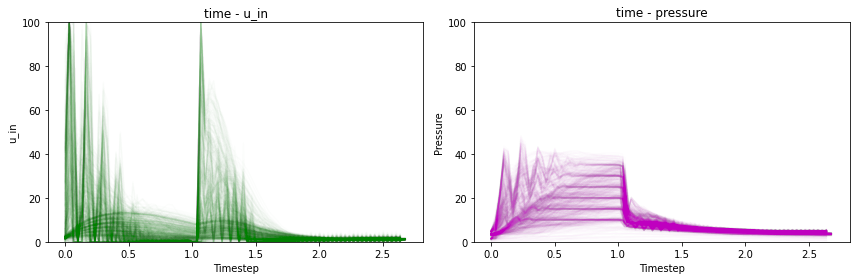
結局,u_inの大きい動きを入れることで何とかならないかと思いローパスを掛けたu_inと,それを用いた特徴量を入れてみました.結果,これは精度向上には繋がったのですが,平行ずれはとれませんでした.
ソリューションを見ると,やはりu_inが近い距離のデータを用いた特徴を効かせていたチームもありました.
また,チームの方がこの段階から積極的にアンサンブルを行っていたため,チームとしてのスコアもどんどん伸びていきました.
アンサンブルでは,シンプルに中央値(MAEの場合,平均より中央値のほうが良い)を取ったものか,optunaで重みを最適化して中央値を取ったものを用いていました.
終盤
終盤では,LSTM + Transformerのモデルに変更しました.また,fold数を増やすと顕著にスコアに効いたということで,
結局,私のシングルモデルのベストは20foldでCV: 0.1344 LB: 0.1187 でした.
しかし,金圏付近の他チームの伸びがすごく,残り一週間時点で20位付近まで下がってしまったため,私達も何かあと一つ強みを発見しないと金メダルは取れないと試行錯誤していました.(また何かに気づいてかなり高いスコアを出しているチームもありました)
ポストプロセスとして,cosine類似度を用いてu_inの類似度がtrainデータととても高いtestのデータがあったら,trainデータの圧力値をtestに用いる作戦を考えました.
これは特に,u_inが全て0という特殊なbreath_idの予測を救済しようと考えたためです.しかし,あまりうまく行きませんでした.
結局,スタッキングがとても効きそうなことをチームメンバーが発見し,残り数日で一斉にみんなでスタッキングモデルを作成しました.
lgbm,Xgboost,mlpなどが寄与していたと思います.
スタッキングは二段目まで行いました.一段目と比べて精度が向上すれば三段目まで行おうとしましたが,思ったより伸びなかったため,
最終的には一段目のスタッキングモデルの重み最適化した中央値アンサンブルと,二段目のスタッキングの重み最適化した中央値アンサンブルを提出しました.
結果と反省
結果,17位で金メダルにはわずかに届きませんでした.残念…

終了後に世間を賑わせていたリークについてですが,これはu_inが測定された圧力値によりPID制御されていることから,pressureを代数計算で出せるというものでした.
1位はtestデータの66%を完璧に当てることが出来ていたようです.
[#1 Solution] PID Controller Matching (V1) | Kaggle
進め方的な反省としては,pytorchで精度が出にくかったの少しありますが,やはりチューニングに時間を掛けすぎたかなと思っています.
普段こんなにハイパラチューニングに時間をかけることはないのですが,もともと精度の高い争いになっていたためか(MAEで0.1台って普通にすごい),
この辺の設定値がスコアに直結してくる印象でした.
最終的には80epochで回せるモデルを作れたのは良かったのですが,もっとホストの論文やリポジトリに目を向けるべきでした(読んでいたとして,リークに気づけたかはアレ) .
データがどう作られているかはデータの特性を掴み,ホストの論文をちゃんと読めばわかることでしたので,きちんと取り組まなかったことが悔やまれます.
まとめ
今回のコンペはリークに気づけたチームが大きく精度を伸ばす結果となりましたが,リークを用いなかったチームも金圏に複数あったのも事実ですので,悔しいです.
その一方で,シングルモデルの精度では,金メダルのチームに負けずとも劣らずの性能を出せていたと思うので,そこはちょっと自信になりました. (とは言っても,まだまだですが)
終盤は他チームのスコア変動がとても激しく,精神的負荷が半端じゃなかったです.チームメンバーがいなければその中で戦えなかったと思うので本当に感謝です.
金メダルを取るのは本当にむずかしいですが,今後も挑み続けていきたいと思います.
自分のベストモデルのコードです,ご参考までに.