kaggle 鳥コンペ3 振り返り
はじめましての人ははじめまして.普段sqrt4kaidoという名前でkaggleのコンペなどに参加しています.本記事では,先日まで行われていたBirdCLEF 2022(通称: 鳥コンペ3)の振り返りを行いたいと思います.かなり長くなってしまったので,目次を参考に適当に目を通していただけたら幸いです.
(kaggle discussion版はこちら)
コンペの説明
今回のコンペは三回目となる鳥の鳴き声を検出するコンペで,特筆すべき点としてはハワイで絶滅の危機にある希少な鳥の鳴き声の検出が目的であることです. したがって,テストで対象となる鳥が主にハワイに生息する種21種に絞られていて,中にはtrainデータに1つのwavファイルしか存在しないものもありました.(trainデータは152種)
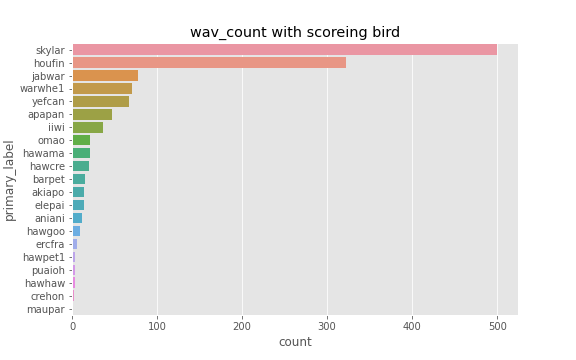
採点は,約60秒のwav5500個と,それぞれのwavでどの鳥を検出対象とするかが与えられます.参加者はそれに対して,検出対象の鳥が鳴いているか5秒単位でTrue/Falseを割り当てるコードを提出します. 評価方法は特殊なf1スコアで,正のクラスと負のクラスのスコアが等しくなるような重み付けをし,それを各鳥で算出,その後平均を取るようです.
実験と解法
結果から
今回は完全ソロで挑み,35位で銀メダルという結果に終わりました.序盤〜中盤は5位以内をキープしていただけに,なんとも言えない結果になってしまいました.
反省点は多々あるにしろかなり知見を得たコンペになったので,この記事でどんな実験をしてどんな知見を得たのかを放出したいと思います.
特徴量
昨今の音関連の深層学習モデルといえば,波形から画像を生成し特徴量とすることが多いです.その中でもよく用いられているのはメルスペクトログラムという画像形式なのですが,よりノイズに頑健な方法だったり,別のメルスペクトログラムからの変換方法を検討しました.
- pcen
Per-channel energy normalization(pcen)は,メルスペクトログラムのlogを取る代わりに,特殊な正規化を行います.この処理によりできた画像は,時間方向に変化量の多い周波数帯が強調され,変化の少ない周波数帯が抑制されたノイズの少ない画像になります.kaggle上のnotebookがとてもわかりやすいです.かなり期待して実験を行ったのですが,私の手元ではスコア向上にはつながりませんでした.
- linear spectrogram
そもそもメルスペクトログラムというものはスペクトログラムに対し,人間の耳に聞こえるような周波数帯を強調させるようなバイアスをかけて移動平均を取ったものです.(このどう移動平均を取るか決定づける行列は,フィルタバンクと呼ばれます.)このバイアスの種類により生成される画像が異なります.
本コンペでは,人間の耳に聞こえづらい周波数帯にも鳥の声の特徴が存在するのではないかと考え,バイアスなしの移動平均を用いた画像(勝手にlinear spectrogramとよんでいますが)を作りました.しかし,こちらも精度向上には至りませんでした.
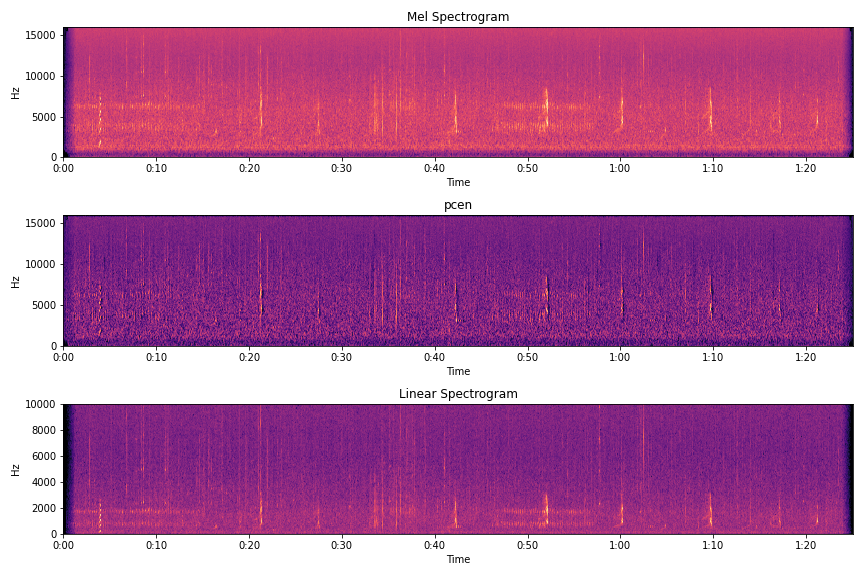
またこれはtipsなのですが,torchaudioを用いたメルスペクトログラムと,librosaを用いたメルスペクトログラムは,微妙に見た目が異なります.
同じ事象が,logを取る際にも発生します.これらの整合性のとれるコードをkaggle上にアップロードしますので,少々お待ちください→作成しました.
結局通常のメルスペクトログラムを用いるのが一番スコアが良かったです.1の案も2の案も,メルスペクトログラムと組み合わせたり,チャネル毎に用いる周波数帯をずらしたりしてみましたが,効果はありませんでした. ちなみに上位解法を見ると,CQTを用いて精度が向上したとの報告もありましたので,これはぜひ次回に活かしたいと思います.
モデル
今回,モデルは大きく3種類のアーキテクチャを検討/実装しました.
- PANNsベースのモデル
これはおなじみの方にはおなじみの,あらいさんモデルをベースにしたものです.詳細なアーキテクチャは本家ノートブックをどうぞ.クラス分類結果をフレーム単位で出力することができるため,Sound Event Detection(SED)タスクにはもってこいのモデルになっています.変更点としては,より時系列的な特徴を捉えられないかと,backboneに通した後のLinear層をLSTMに変更しています.これは若干の精度向上につながりました.
- STFT Transformer
これはCPMPが去年の鳥2コンペで考案したもので,ViTの入力にメルスペクトログラムを取れるようにしたモデルです.(本家実装)
特徴的なのは画像のパッチの作り方で,ある短い時間の全ての周波数帯が1つのパッチに入るように整形します.(メルスペクトログラムを縦に切るイメージ)メルスペクトログラムは通常の画像と違い縦方向は絶対的な値,横方向は時系列的な値になっています.この時間方向の関係性を捉えるためにパッチの作り方として,個人的にとてもしっくりくる手法です.
去年の鳥コンペ2ではCPMPがこれを用いて高いスコアを出していたのですが,私の実験ではPANNsのスコアを超えることは出来ませんでした.
- STFT Swin SEDモデル
これはコンペが始まった当初から実装したかったモデルで,上記STFT Transformerをベースとしつつ,フレームごとのクラス分類結果を出力できるようにしたモデルです.
上記STFT Transformerはフレーム単位でのクラス分類結果は出力できないため,STFT Transformerと同じようなアーキテクチャでよりSEDタスクに適した機構をつければスコア向上につながると考えました.今年の頭にSwin Transformerを用いたSEDモデルの論文が出ていたので,これを参考にパッチの埋め込み方をSTFT Transformerに変更したモデルを実装しました.
しかしこちらも,PANNsのスコアは超えることが出来ませんでした.
モデルに関しては,上位解法もほとんどPANNsベースだったように思います.Transformerは画像全体の特徴を見るのが得意とのことなので,単発的な鳥の声を分類するよりは定常的な音の分類などのほうが適したタスクなのかも知れません.
class imbalanceへの対応
学習データはかなり不均衡で,また評価対象の21種もかなり不均衡だったため,これの対処が肝だと考えました.したがって,この分野の調査にはけっこうな時間を費やしました.
- オーバーサンプリング
これに関しては以下の2種類スコアが向上した手法があります.
不均衡さを少しでも補正するため,wavの数が20を下回る種のwavに対し,オーバーサンプリングを行いました.またこの際,オーバーサンプリングしたものを過学習することを防ぐため,オーバーサンプリングを施したwavのみに対しaugmentationを強くかけました.これは少しスコアが向上しました.
Context-rich Minority Oversampling(CMO)とよばれる手法を用いました.これはCutMix時に少ないクラスをオーバーサンプリングするというとても単純明快な手法で,メルスペクトログラムに対して適用しても効果がありました.時間方向にのみCutMixするなど切り方を工夫してみましたが,単純なCutMixが一番良かったです.これは予想ですが,(マシンスペックが許せば)バッチサイズを大きくしたほうが各バッチで不均衡さが大きく出て,この効果がより現れる気がします.バッチサイズが小さいと,そもそも少ないクラスがバッチにないことが多かったり,多数派のクラスも1つしかサンプリングされない,なんてこともざらにありそうです(論文は128とかそれ以上の数を使っていました).
また,weightedrandomsamplerを用いて不均衡クラスを多めにサンプリングするということもやってみましたが,スコアは向上しませんでした.これは今思えばこれはCMOと相性が悪いように思います.
- lossの検討
focal loss以外のclass imbalanceに有効なlossもいくつか検討しました. CBLoss,ASL,IBLossと実装してみましたが,結局focal lossを超える精度は出せませんでした. 中でもepochの半分から決定境界付近にあるサンプルのweightを下げるIBlossと呼ばれる手法は,かなり期待を持って実装しましたが,CVスコアは伸びたもののPublicのスコアは向上しませんでした.
ローカルにおける評価方法
今回の評価方法は非常に掴みづらく,またCV/LBの相関が取れないということで,discussionでもスレが立っていました.私は以下のようなコードでCVスコアを計算していましたが,結局LBとの相関は全然取れませんでした.したがって,評価対象21クラスに対するこのメトリックスコアと,全152クラスのf1スコア(samples)を様々な閾値で計算し,それらが過半数程度上回っていたら提出するという作戦を取っていました.
def calc_tpr(true, pred, threshold): true = (true > 0.5) * 1 pred = (pred > threshold) * 1 tp = np.sum(true * pred) fn = np.sum(true * (1-pred)) tpr = tp / (tp + fn + 1e-6) return tpr def calc_tnr(true, pred, threshold): true = (true > 0.5) * 1 pred = (pred > threshold) * 1 tn = np.sum((1-true) * (1-pred)) fp = np.sum((1-true) * pred) tnr = tn / (tn + fp + 1e-6) return tnr class Metric(): def __init__(self): self.tgt_index = list(map(lambda x: CFG.target_columns.index(x), CFG.test_target_columns)) def calc_tgt_f1_score(self, gt_arr, pred_arr, th, epsilon=1e-9): scores = [] for i in self.tgt_index: a = list(gt_arr[:, i]) uni_, counts = np.unique(a, return_counts=True) # posi_weight = counts[0] / len(a) # nega_weight = counts[1] / len(a) posi_weight = 0.5 nega_weight = 0.5 tpr = calc_tpr(gt_arr[:, i], pred_arr[:, i], th) tnr = calc_tnr(gt_arr[:, i], pred_arr[:, i], th) score = posi_weight * tpr + nega_weight * tnr scores.append(score) return np.mean(scores)
推論処理
testはf1スコアベースの評価方法なので,True/Falseを決める閾値が重要になってきます.今回のコンペではかなり低めの閾値が適しているようでしたが,この原因は2つあると考えています.
- testデータではかなり正のクラスが少ないため,FPRが高くなったとしてもTPRを高めるのが大事なため
- 特に少ないクラスでは決定境界がかなり狭まっているため,閾値をかなり低くしないと正と判断されないため
二番目の理由については,逆に言えば多数派のクラスは閾値を高くしても正のクラスを検出できるのではないかと考え,最終的には閾値をクラスごとのデータ数を元に決定しました.例えば,一番学習データが多いクラスの閾値を0.3,一番少ないクラスの閾値を0.05に設定し,残りはデータ数を元に線形にスケールさせました.
またもう一つ工夫点があります.当初あるwav内に鳥が見つかったら,wav全体のそのクラスの予測確率を0.2上乗せするという後処理を行っていました.しかし,例えば閾値を0.05に設定している場合,0.2上乗せするとそのwav内は全ての秒数で対象のクラスの鳥が検出されていることになります.したがって,私の推論では評価対象21種中学習データが少ない(=閾値が0.2を超えない)19種の鳥において,音ファイル単位での予測しかしていません.wav内に鳥が見つかった際の後処理に関しては何パターンか検討しましたが,このスコアが一番良かったです.
その他後処理に関しても色々試行錯誤しましたが,スコア向上にはつながりませんでした.以下に例を上げます.
- 画像処理を用いてメルスペクトログラム中に単発音のようなものが表れているか検出.検出されない区間はどの鳥も鳴いていないと判定.
- 共起行列を用いて,一番予測確率が高い鳥と一緒に鳴いている可能性のある鳥の予測確率を高める
その他効かなかった実験
緯度経度をターゲットとしたモデルを作り,ハワイのみに生息する種においては,ハワイ以外の音と判定された時点で対象の鳥は鳴いてないと判定しました..
このモデル単体ではpublicで0.6くらい出ていたのですが,既存のモデルと組み合わせて精度は向上しませんでした.
pseudoラベルは,5foldのoofを用いて追加のsecondary_labelを追加したり逆に怪しいものを削ったりしてみましたが,
どれも効きませんでした.手作業でラベル付して精度が向上したとの報告をいくつか見たので,元のモデルの精度が足りなかったのかも知れません.
感想など
まずshakeについてです.私の予想では,大規模なshakeが起こると思っていました.publicのテストでは21クラス中半分のクラスも使われていないからです.鳥がprivateとpublicでクラスがまんべんなく分かれているのであればシェイクはしないかも知れませんが,publicにいない鳥の種が多いとなるとかなり揺れるだろうと踏んでいました.しかし,蓋を開けてみればそこまで揺れは大きくありませんでした.ならばなぜCVとLBの相関が取れなかったのかということですが,単純にホストとローカルの評価に用いるコードに違いがあったか,もしかすると音のモデルの評価にはどこで集音されたか,つまり周りの環境音がかなり寄与するのかも知れません.
続いて総括です.振り返ってみると,私はモデルの改良とインバランス対策の二点を重点的に対策していました.上位陣の解法と比較しても正直あまり違いはなかったので,金メダルを取れなかったのが悔しいです.進め方については今回のようなCV/LBで相関が取れないコンペでは,はやいうちに自分のスタンスを決めるべきだと痛感しました.例えばTrust CVで行くのか,とりあえず全実験を提出してTrust LBで行くのか…などです.(そもそもこういうコンペには参加しない,という手もあります)コンペ終盤は,相関は取れないし最後1ヶ月まったくスコアを伸ばすことが出来ないし,ソロなので相談できる人もいないしで,今までで一番精神的にきつかったです.しかしkaggleのコツは狙ったメダルが取れなかったくらいで諦めないことだと思っていますので,これからもがんばります.
ちなみにコンペ自体は,ホストのモデルが結局最強でしかもこれの使用許可が終了二日前におりるといったこともあり(参考),2022年ク◯コンペにノミネートされそうですが,まあ学びは多かったのでOKです(ほんとか?)
最後は感想超えて反省超えて呪詛のようになってしまいましたが,以上で振り返りとしたいと思います.読んでくださった方ありがとうございました.