2025年振り返り
今年も瞬く間に年末を迎え、進捗の無さに震える頃合いですが、いかがお過ごしでしょうか。私に関して言えば、2024年の年末にGrandmasterになってから早一年が経ちまして、今年は一言で言ってしまえば虚無な一年でした。したがって、逆にどんな一年だったかブログに残そうと思い、筆(パソコン)を取りました。
何も考えずにkaggleに挑戦し続けるのは辛い
去年まではGMになるという明確な目標があったので、大変な中でもモチベーションを高く保ってkaggleに取り組めていました。今年は目標を達成したことでそんな状況が一変し、半分惰性半分仕事、のような感覚でkaggleに出続けました。しかし、これが単純に辛い。すぐに、なぜ自分はこれに取り組んでいるんだろう?という意味のない自問自答をしてしまう。後半はチームを組むことでなんとか踏ん張っていましたが、最終的な金圏にたどり着くための詰めでうまくいかない。といった状況がずっと続いていました。GMになってもkaggleに取り組んでいる人は、なぜ続けているのでしょうか?いつまで続けるのでしょうか?
そんなこんなで今年のコンペの結果は散々なものでした。金メダルを1枚も取れないだけではなく、特に夏以降取り組んだコンペに関しては
- CMI3: shakeでメダルなし
- Mitsui: 評価期間中のエラーで順位なし
- NFL2026: 評価期間中のエラーで順位なし
という悲惨なものでした。evaluation APIとかいうの、やめません?time series APIは得意だったのにどぼじで…一応、鳥コンペ2025でソロ16位、atmaCup20でソロ4位にはなりましたが、GMに見合った成績ではないですね。
もう少しbadな取組み方の解像度を上げると、リーダーボード上で抜かされたのが気になって小手先の取り組みばかりしてしまうんですよね。データの性質をよく分析/観察することの大切さはよく分かっているはずなのに。これは取り組み方として非常に良くないと思っています。総括して、コンペに関しては大分疲弊してしまっているのが現状です。

どこもかしこもエージェント開発
最近では「AIエンジニア」というと、機械学習モデリングを行う人ではなく、APIを駆使してAIシステムやエージェントを作る人を指す、という派閥もあるようです。ますます自分の職業を何と名乗ったらいいかわからなくなってきました。受託案件やPoCとしても、機械学習モデリング単体の案件は減っていき、その代わりにエージェントの案件や、機械学習→エージェントへの組み込みまで視野に入れたものが増えてきている感触があります。
さて、困ったことに現状上記の開発にあまり興味が湧いてきません。というよりLLM自体にあまり興味が向いていません。それも相俟って、仕事に関してもあまりモチベーション高く取り組めなかったなと反省しています。(その分数少ない機械学習単体案件に関しては逆に貪欲に取り組んでいた気もしますが)今後のキャリア、皆さんはどう考えているのでしょうか。
2026年へ向けて
kaggleを続けていくのか、そもそもAI業界に居続けるのか、充電期間に入るのか…色々な選択肢があると思っています。私は基本的に怠惰な人間で、特に技術が好きという訳でも無いです。したがって、kaggleのようなある程度プレッシャーのある環境に身を置かないと勉強を頑張ることができません。もしkaggleを辞めた場合、研鑽やAI関連のキャッチアップがさらに大変になってしまうだろうなという恐怖感があるのです。(同じような理由でTwitterもやめられない)
GMになってからの方が辛いとは正直思っていませんでした。大きな目標を達成して少しは自分に自信を持てるかなと思いましたが、結局人間の根幹はそれほど簡単に変わらないようです。 ちなみに未来に向け何も行動していない訳ではなく、秋頃から他社のお話を聞くなど情報収集をはじめています。怠惰なりにハリのある人生にして行きたいとは思っているので、2026年の年末には、これに力を入れていくというものが(AI以外でも、何なら仕事以外でも)自分の中で決まっていることを願うばかりです。
では、良いお年を。
Kaggle Competition Grandmasterになるまでの振り返り
あけましておめでとうございます。前回のコンペ振り返りからだいぶ時間が経ってしまいました。Kaggle Masterになってから早3年半近く、この度ようやくKaggle Competition Grandmasterになりました。ここで先人に倣って(?)、一度印象深いコンペを取り上げつつkaggle遍歴を振り返ってみようかなと思います。
なお、技術的な振り返りではなく、感想とポエムからなる駄文であることをご了承ください。
初参加~Masterまで
未経験からkaggle挑戦初期
学生時代に情報/画像処理を学び、新卒で入社した会社ではカメラの組み込み/アプリエンジニアとして働いていました。しかし色々あった後心機一転転職した先が、音声処理や異音検知を行う会社でした。そこではwebエンジニアとして働く予定でしたが、入社直前のタイミングで機械学習エンジニアをしてみないかと打診がありました。これに対し何もわからないままハイ!と二つ返事したことから、機械学習エンジニアとしてのキャリアが始まりました。入社して数ヶ月経ったタイミングで某コ□ナが流行り始めたことでおうち時間ができたため、kaggleにはこのタイミングで挑戦し始めることになります。しかし最初の数コンペはなかなかどう進めていいかもわからず、高スコア(overfitting)公開ノートブックをちょっと変更するだけ。結果も箸にも棒にもかからず…な状態でした。
Cornell Birdcall Identification (114th🥉)
最初に銅メダルを獲得したコンペです。毎年開催されている通称「鳥コンペ」の第一回目で、鳴き声から鳥の種類を判別するタスクでした。業務でも音を取り扱っていたため、知見を深めるべく参戦しました。印象深いのは、pannsという明らかに有用なモデルが公開ノートブックで紹介されていたのに、それを用いて学習しても全然精度が向上しなかったことです。ハイパラを含めたNNモデルの学習の難しさを知りました。また、まずディスカッションを理解するのが大変だったのを記憶しています。
公開ノートブックのスコアをなかなか抜かせずにいたところ、同じくこのコンペに参戦していた先輩に誘っていただき最終的にアンサンブルでなんとか銅メダルに食い込むことができました。
MLB Player Digital Engagement Forecasting (6th🥇)
最初に金メダルを獲得したコンペです。テーブルコンペという題材と、前日の結果などから野球選手の人気(エンゲージメント)を予測するというタスクに魅力を感じ、参加しました。コンペ期間が終わった後、実際に取得されたデータで3ヶ月かけて評価していくのも面白そうだと当時は感じていました。コンペ期間中にソロで金圏内に入ったタイミングで、野球のドメイン知識が豊富な方々に拾っていただき、最終的にはチームで参加しました。
Time Series APIというkaggle独自の提出システムがあり、これに対応するのが大変でした。例えば次の日の推論に前の日の正解データは使えるのか?などなどが不透明のままコンペが進んでしまったので、終了直前までホストに質問しつつ、なるべくエラーが起きないような実装を心がけました。評価期間に入った最初の評価実行で約半数のチームのサブが通らずに一気に約半数になったのを覚えています。Time Series APIのコンペはあまり開催されないですが、個人的には好きなコンペです。(最初の評価実行でライバルが減るから)
Masterになってから
番外編 kaggle days championshipへの参戦
2021年末から2022年夏頃まで、各都市の名を冠したオンライン予選が行われ、各予選の4位以内がバルセロナで行われた本戦(+イベント)に招待されたというイベントです。 予選は4時間という超短期コンペで、何回でもチャレンジすることができました。この超短期コンペが面白く、深夜以外は毎回のように参戦していました。丁度Tokyoの予選の際に優勝することができました。優勝した回は欠損値を予測するタスクだったのですが、機械学習の予測で埋めてしまうと平均値埋めに比べ悪影響を及ぼすデータがあり、これを発見できたことが優勝につながりました。
2022年10月末に行われたバルセロナのイベントは、とても楽しかったです!!!私自身初めての海外渡航がこのイベントだったので、時差ボケなどがとても不安でした。しかし有無を言わさぬような早朝からのスケジュールで、時差ボケかどうかわからないほど寝不足の中イベントに参加したのを覚えています。コンペ本戦の結果としては全然振るわなく、同時に日本チームが優勝していたのでここでも力の差を痛感しました。ただ、この予選/本戦でチームを組んだ方々とは今でも交流があり、その点でも参加して良かったと思えるイベントでした。
ちなみに、本戦前のタイミングで今所属している会社に転職しました。
1st and Future - Player Contact Detection (5th🥇)
動画とテーブルデータから、アメフト選手の衝突タイミングを検知するコンペです。マルチモーダルコンペで、できることがたくさんありそうと思い参戦を決めました。 動画データを用いた学習を1st stage、1st stageの予測と他のテーブルデータ特徴量を使った2nd stageからなる2stageモデルで行こう!と最初から決めて取り組み始めました。 私は後段の決定木モデルに力を入れていたところ、ちょうど組ませたいただいたチームが強力な1st stageモデルを持っていたので、うまく噛み合ったのを覚えています。肝となった1st stageのモデルは結局チームメンバーに任せっきりだったので、ここでもNN力のなさを痛感しました。
ただ、このコンペは選手のヘルメットのバウンディングボックスがあらかじめ与えられていました。その割り当ては前年度の関連コンペにおける優勝ソリューションを元に予測されたとのことだったのですが、これがなけでばスタートラインにすら立てていなかったと思うと、まだまだ勉強不足だと感じました。
NFL 1st and Future - Player Contact Detection 振り返り - :D
Parkinson's Freezing of Gait Prediction (13th🥈)
歩行時の加速度計のデータから、歩行にパーキンソン病特有の症状が発現しているかどうかを判別するコンペです。2022~3年頃から、音データに加えてセンサーデータなどの系列データにも積極的に参加し始めました。共通して使えるテクニックが多かったことと、画像、NLP、テーブルよりはおそらくライバルが少ないところを自分の強みにできるのでは?と感じたためです。
このコンペは悔しい結果として記憶に残っています。最終的にセンサーデータをそのままモデルに突っ込んだり、画像化したりして作成した様々なモデルをアンサンブルしたのですが、私の方で選んだサブがギリギリで金メダルに届きませんでした。しかも私のサブはprivateデータに対するスコアがあまり良くなく、チームメイトにも迷惑をかけてしまう形となりました。
これが悔しすぎてコンペ振り返り記事が途絶えました。
HMS - Harmful Brain Activity Classification (9th🥇)
EEGという脳波信号から特定の疾患パターンを判別するコンペです。特にデータをどのようにモデルに入れるかという点に関して、試行錯誤がうまくハマったのがこのコンペです。またアノテーションの方法までしっかり確認してそれをモデリングに用いたりと、色々と工夫できました。
転職して初めて社内メンバーのみのチームで臨んだコンペでした。 結果的には金メダルを取れたのですが、金圏下位から優勝争いに食い込むためにはもう一伸び二伸び無いとダメだと感じました。(特に終盤失速しがち)
LEAP - Atmospheric Physics using AI (ClimSim) (7th🥇)
機械学習を用いた気象モデルのシミュレートを行うタスクです。HMSコンペに続いて臨んだコンペで、色々あって締め切りが2週間ほど伸びたのが記憶に新しいです。 実験を高速に回すために7000万データの学習を最後の最後まで取っておいて、最終日の前の日からこれを使った学習をsubに組み込んだところ、チームに順位が大きく伸びて一気に金圏に入ったのを覚えています。
Child Mind Institute — Problematic Internet Use (7th🥇)
被験者のアンケート結果やセンサー値などから、問題のあるネットの使用を予測するコンペです。2023年のCMIコンペで大敗を喫したので、同じホストでセンサーデータもある!リベンジだ!と意気込んで始めたコンペです。しかし、実際はセンサーデータの勝負にはならずにテーブルデータとして与えられた個人の属性やアンケート結果などを用いた単純な決定木の学習を行いました。しかも学習データ量が少なく、publicにoverfitした公開ノートブックが猛威を振るっていたことから大幅なshakeが予想されるいわゆる宝くじ要素の強いコンペとなりました。とっつきやすくはあったので参加者は多く、3600チームほどリーダーボード上にありました。
結果としては予想通り大きなshakeが起こりました。自分はCVだけを信じ、まあshakeで上がるだろうけど金まで行くかは運次第だな〜下手したらメダル取れるかも怪しいな〜くらいの気持ちでいたので、いざ終わって見ると金メダルしかもprize圏内でびっくりしました。蓋を開けてみるとCVとPrivateデータのスコアは(自分の場合)それなりに相関していたようです。
ソロで勝負できそうなコンペに関してはソロで行こうと決めていたのですが、Enefit、LLM20Q、ISIC2024と金メダルを取れていなかったので、このタイミングで取得できてとても嬉しかったです。
おわりに
振り返ってみました。決まった時間にこれをやれ!と言われるとかえって集中力が続かないタイプなので、自由に取り組めて期間も長いkaggleは自分にあっていたように思います。また、いい感じのプレッシャーがないと勉強が続かない怠惰な人間なので、kaggleへの参加自体が勉強へのいいモチベーションとなっていました。
これまでなあなあに生きてきてしまったな〜と感じることが多かったため、自ら達成難易度の高い目標を設定し、数年がかりで達成できたことが非常に嬉しいです。Grandmasterという称号自体の価値を落とさぬよう、これからも研鑽を続けていこうと思います。
NFL 1st and Future - Player Contact Detection 振り返り
はじめましての人ははじめまして。普段sqrt4kaidoという名前でkaggleのコンペなどに参加しています。本記事では、先日まで行われていたNFLで5位に入ることができましたので、その振り返りを行いたいと思います。
概要
本コンペは、The National Football League (ナショナル・フットボール・リーグ、以下:NFL)の試合中におけるプレーヤーの外部接触を検出するタスクでした。タスクの実施にあたっては、試合の動画データとトラッキングデータなどのテーブルデータが与えられました。提出はコードコンペティションの形式で行われました。
データ
動画は、全体が映ったものと、ゴール側(EndZone)、サイド側(SideLine)から撮られた3種類が提供されました。EndZoneとSideLineの動画は同期が取られており、後述するテーブルデータとも簡単にマージすることができます。それぞれの動画は、1つのplayが始まってから終わるまでの約12~15秒間で区切られていました。
テーブルデータは、以下の4種類が与えられました。
- trackingデータ
- helmetデータ
- labelデータ
- 動画のメタデータ
trackingデータは、各選手につけられたセンサーから取得されたデータで、ポジションや速度、加速度といった情報が含まれています。helmetデータは、昨年のソリューションから出力された各動画のヘルメットの座標です。このデータがあるおかげで、私のようにあまりコンピュータビジョンに造詣が深くない人も参入しやすい動画コンペだったと思います。labelデータは対象の動画の秒数においてplayer1とplayer2、もしくはplayer1とG(地面)にcontact(接触)があったかを表すデータです。
trainには149のgameにおける233のplay動画が提供されました。ラベルデータは4721618行存在します。 test時は61のplay動画に対して推論を行います。
ベースライン
多くの人が参照したであろうベースラインについて紹介します。
NFL 2.5D CNN Baseline [Inference] | Kaggle
このベースラインでは、各ラベルに対して
- 前後数frameの画像
- trackingデータ
をそれぞれCNNのバックボーンとmlpに通した後concatして全結合層に通すモデルです。各frameの画像は、helmetのbboxを用いて切り出されます。 ラベルを全て使うと途方も無い時間がかかってしまうため、事前に計算された各ラベルのplayer同士の距離が2ヤード以上のラベルは最初から衝突無しと判断し、学習/予測対象に含まれないようになっています。
しかしそれでもこのベースラインは学習に1epochあたり1時間程度かかりました。したがって、精度向上を行うとともに効率的な学習方法を模索するのもこのコンペの肝の一つでした。
弊チームソリューション
チームのprivate5位ソリューションのポイントを紹介します。詳細な解法はkaggleのdiscussionに上がっています。
1st and Future - Player Contact Detection | Kaggle
私たちのチームのソリューションは、2stageで構成されています。
- stage1 : 画像を中心としたCNN(+LSTM)モデル
- stage2: stage1の予測値を利用した決定木モデル
それぞれについて説明します。
stage1
stage1は、動画から抽出した画像と、一部のtrackingデータを利用します。以下にモデルの全体像を示します。
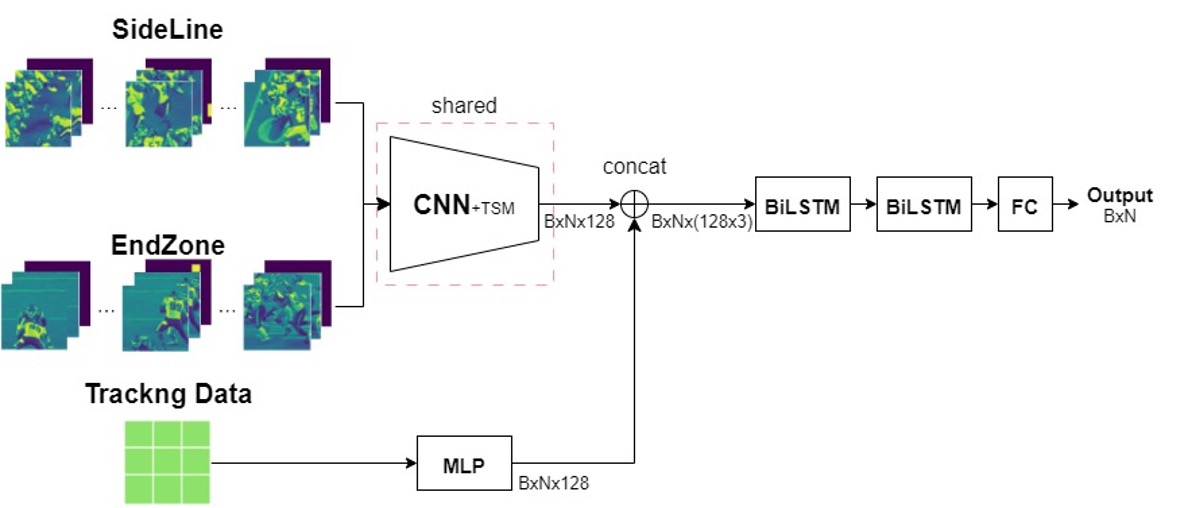
一番重要な部分は、outputの形状部分です。ベースラインではラベルの一行あたりに注目するため一回の学習の出力が(B, 1)ですが、 私たちのモデルでは(B, N)で出力します。Nとはシーケンスの長さです。次にシーケンスについて説明します。ラベルを衝突対象playerの組み合わせごとに時系列で並び替えると、各組み合わせごとに以下のような一連の時系列として現れます。シーケンスはこの一連のラベルから32などの固定長で切り出します。
このモデルでは、入力で作成したシーケンス長を一気に学習することができるため学習/推論にかかる時間を大幅に短縮できます。モデルやシーケンス長次第ですが、1epoch約10~15分で完了していました。また、このシーケンスごとに学習する仕組みのせいか、TSMやLSTMといった時系列特徴を学習できる仕組みが精度向上に寄与していました。
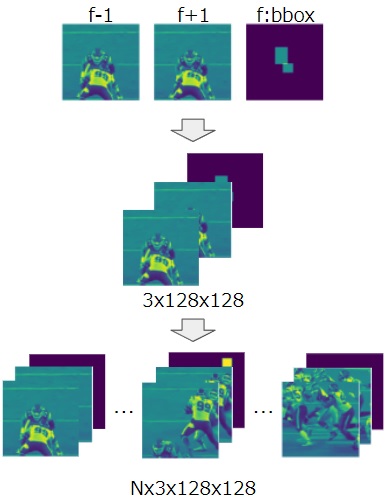
モデルへのinputは((B x N) x 3 x 128 x 128)の形状となっており、チャンネル数の3は以下の画像のように対象フレームの前後と、対象フレームのヘルメットbboxから作成されます。
stage2
stage2はstage1のCNN予測値を中心に特徴量を抽出します。上記シーケンスや、playごとなどさまざまな集約特徴量を作成しました。しかしCNNの予測値のモデルへの寄与がとても大きかったこともあり、作った特徴量は効かないものがほとんどでした。
他の工夫点として、 stage2のモデルではCNNと同じtrain/validの切り方を行います。したがって、stage1が5foldの場合stage2も5つモデルができます。 また、player1と2は無向なので、player1と2を逆にした特徴量を作成しデータ量を二倍にしました。最終的な予測は、平均を取ることで算出されます。 モデルはlgbmとxgboostを用いました。 特徴量抽出は全てpolarsで行っています。
推論
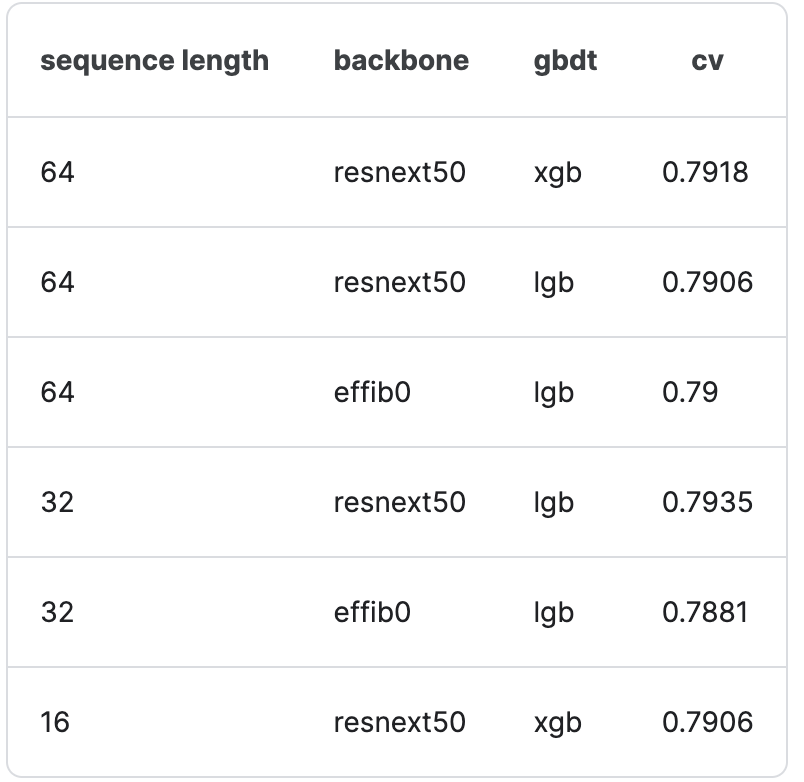
推論時には、さまざまなシーケンス長さで学習したモデルを使用することで、サブの多様性が増すように工夫しました。また、シーケンスによってはストライド幅を短くし、重複して推論させることで精度が大幅に向上しました。最終的には、oofで最適化された以下のstage2モデルを用いました。
予測値を0/1に直す閾値は最適化の際に求められたパーセンタイルによって決定されます。
その他高速化のtipsを以下に示します。
- PyTurboJPEGを利用することで、1.5倍ほど画像読み込み時間を短縮しました。opencvと様々なライブラリを比較しましたが、PyTurboJPEGが唯一画像読み込みを高速化できました。numpyに変換する方法も試しましたが、容量を多く使うので不採用となりました。
- 推論時は画像読み込み関数にlru_cacheを用いることでキャッシュを効率的に利用できました。
- ffmpegの画像抽出の画質は、多少下げても精度にはほとんど影響しませんでした。(具体的には、2から10まで下げました。)これにより画像抽出時間と、画像読み込み時間を高速化することができました。
上位解法紹介
利用できるデータの種類が豊富だったため、さまざまなソリューションが上がっていました。その中から2つ簡単に紹介します。
1st
1st and Future - Player Contact Detection | Kaggle
1位は、
- xgboostで簡単なネガティブサンプルを除去
- CNN
- xgboost
というパイプラインでした。1でネガティブサンプルを除去することで2以降のデータ量を減らし、実験を効率化しています。この流れで解いているチームは結構多かったように思います。 また特徴的な点として、trackingデータを画像化してCNNへinputしています。
3rd
1st and Future - Player Contact Detection | Kaggle
3位の解法は打って変わって1段階のアプローチになります。モデルが非常に複雑ですが、outputに着目します。 具体的には、対象のプレーヤーから近い人7人において接触があったかどうかを一気に出力するモデルになっています。 ベースラインがある特定の時間、空間における学習/推論だとすれば、私たちのソリューションは時間的に幅を広げたモデルになっていて、3位の方はさらに空間的にも幅を広げているような印象を受けます。 目を見張るようなモデルの全体図がありますので、ぜひリンク先をご覧ください。
また他には、提供されたヘルメットbboxの修正を行う工夫もありました。
感想、進め方など
今回動画データを扱うのが初めてでしたが、ヘルメットのassignmentデータが提供されていたおかげで戦うことができました。逆に言うと、この精度の高いヘルメットのassignmentデータを自ら作り出す力がまだ無いため、computer visionに関してはまだまだ素人だと感じています…
shakeについて
本コンペではテーブルデータを中心にソリューションを組み立てたチームが少しprivateで順位を落とし、逆にCNNを中心としたチームがshake upしました。
これについては上述したシーケンス(固定長に切り出す前)が関係しているのではないかと考えています。trainデータの最短シーケンス長は37でしたが、どうやらtestでは32より短いものがあったようです。
テーブルデータではこの長さが集約特徴量などへ影響しているのではと推察します。
進め方について
このコンペでは開始早々にCNNの予測値をlgbmに入れる2stage制にしようと決めて進めていました。
コンペ中盤でチームマージした際、チームメンバーはCNN単体で高いスコアを出していたので、そこに私の2stage制のアイデアを取り入れました。
しかし終わってみればチームのCNNがとても強く、ほとんどのゲインがstage1にあったと思います。stage2のゲインはモデルやシーケンスによりますが、スコアにして0~0.005程度です。キャリーしていただいたと言っても過言ではないと思うので、引き続きまた金メダルを取れるよう頑張ろうと思います。
G2Netコンペ2023 振り返り
はじめましての人ははじめまして.普段sqrt4kaidoという名前でkaggleのコンペなどに参加しています.本記事では,先日まで行われていたG2Netの振り返りを行いたいと思います.
概要
シミュレートされた重力波干渉計のデータから、連続重力波信号が含まれているかを予測するタスクでした。連続重量波信号はとても微弱であり、ノイズの中から如何にこれを見つけるかが焦点となっていました。それぞれのサンプルにはLIGO Hanford(H1) と LIGO Livingston(L1)から観測された信号をSTFTしたデータ(スペクトログラム)と時間、周波数といったメタデータが一緒くたに入っていました。

データ数は
- train…603個
- test…7975個
と、提供されたtrainデータがとても少ないのが特徴的でした。その代わりホストからデータ生成を行うことができるAPIが提供され、 必要に応じて自分達で追加の学習データセットを作ることができました。
結果
今回私はtattakaさんと2人チームで参加し、Public88位、Privateは17位という結果に終わりました。
我々はCNNを中心としたアプローチに取り組んでいましたが、 蓋を開けてみると、上位の方はアルゴリズムベースの解法を採用していました。
解法紹介
私が取り組んだ解法について説明します。前述したようにCNNをベースとし、データ生成や前処理などを工夫しました。
学習データ生成
色々彷徨いましたが、最終的にはノイズのほとんどない純粋なシグナルとノイズを事前に生成しておいて、学習中にオンラインで足し合わせる方法に落ち着きました。
ノイズ入りのシグナルをあらかじめ生成するのに比べ、より多様なノイズ+シグナルの組み合わせを学習できると考えたためです。
ノイズ生成はこちらのノートブックを参考に、テストのノイズを模倣するようなデータを作成しました。足し合わせる際はスペクトルのパワーを用いたSNRベースの加算を行うことで、どのシグナル/ノイズの組み合わせでも同じような見た目のシグナルの強さになるよう調整しました。
データ数は正例1000個、負例2000個です。
validationには、別で生成したノイズとノイズ入りのシグナルを用い、どのモデルでも同じ評価ができるようにしました。
前処理
少し脱線しますが、コンペ中は、validationでは良いスコアが出ているのにも関わらずtestで同じようなスコアが出ないことに散々苦しみました。
従って、testデータを確認し、生成データには存在しないがtestデータには存在する特徴を細分化し、対策しようとしました。
- 非定常ノイズ…testデータの20%ほどには、時間軸方向に非定常なノイズが含まれていました。
- 観測失敗?データ…ほとんどノイズや信号が観測されていないようなサンプルがありました。
前処理に話を戻すと、この段階では上記1の問題に対して対策を行いました。具体的には、標準化を縦方向に行うことで非定常ノイズのみを消去することができました。
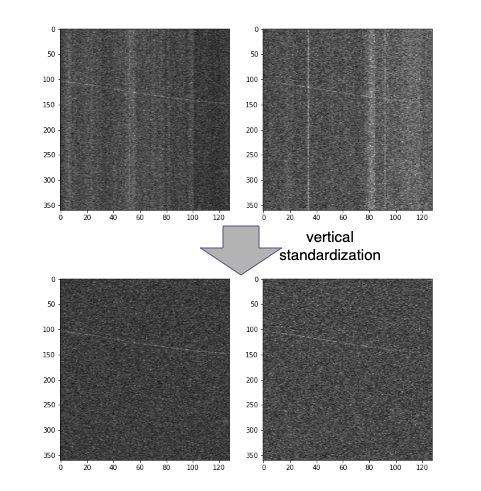
また、cutout, hflip, vflip, hvflipといったaugmentationを行っています。
シグナルやノイズを長めに生成しておいて、学習時にcutoutするaugmentationも効きました。
モデル
モデルに突っ込む前のスペクトログラムにはOR mixupをかけました。
モデルは基本的にtf_efficientnet_b7_nsを用いました。アンサンブルとして、近いスコアが出ていたPANNSアーキテクチャのモデルも用いました。シグナルは全て左端から右端にかけて存在していたため、局所的な特徴に強いCNNよりTransformer系のモデルの方が強いのではないかと実験を行いましたが、うまくいきませんでした。
予測
testデータの予測時には、ttaを行っています、中身としては、cutout, hflip, vflip, hvflip, ch_swapの5つです。また、学習時と同じようにtestのシグナルもcutoutしました。これもかなり効きました。
前処理で説明した「2. 観測失敗?データ」に対してもここで対策を行いました。観測されていないデータは、ほとんどの場合L1かH1のどちらか片方のみでした。従って、
- 前処理をかけた画像の分布から尖度を測定
- L1とH1で乖離が見られるサンプルを抽出
- 2で該当したサンプルは、正しく観測されている方のチャンネルのみを予測に用いる
以上の順番で対策を行いました。
その他工夫
pseudoラベルは、そのまま用いても精度が向上しませんでした。(ソフトラベル、ハードラベル共に) そこでnoisy studentを使ってみたところ、精度が向上しました。OR mixupもそうですが、SETIコンペのアイデアが複数有用でした。
また、アンサンブルはLazy Ensembling Algorithmを用いて相関の高いsubのweightを小さくしました。(これはtattakaさんのナイスアイデアです!)
感想、上位解法との差分
前述したように、上位の方はCNNなどの機械学習手法ではなく、信号を探索するアルゴリズムを用いていました。探索のアルゴリズムは様々ですが、テンプレートとなる信号を用意しマッチングをとることで高スコアを取ることができたようでした。
コンペを進めていく中でも、アルゴリズム系のコンペや競プロも強い方が上位にいたので、アルゴリズムベースのアプローチが強いんだろうなという予想はついていました。じゃあやれよ!!!という話ですが、CV系の方も上位にいたので、我々はそちらを突き詰めていくことにしました。一応ビタビアルゴリズムは試しましたが、SNRの高いシグナルしか検出できなかったため、採用しませんでした。
深層学習を用いる場合、
- できるだけ多様なシグナルを学習させる
- testデータ特有のノイズへの対策
上記2点が本コンペで良いスコアを出すために重要な点だったと考えています。特に2に関しては上位の方と差が出てしまったと感じていて、例えば上位の方はtestで観察されるランダムウォークやラインノイズを混入させていたりしていました。また、testのノイズが使い回されていることを発見し、差分を取ることで非定常ノイズをほとんど消したチームもありました。
金メダルを目指していたので残念な結果にはなりましたが、また金メダル目指して頑張ろうと思います。
kaggle 鳥コンペ3 振り返り
はじめましての人ははじめまして.普段sqrt4kaidoという名前でkaggleのコンペなどに参加しています.本記事では,先日まで行われていたBirdCLEF 2022(通称: 鳥コンペ3)の振り返りを行いたいと思います.かなり長くなってしまったので,目次を参考に適当に目を通していただけたら幸いです.
(kaggle discussion版はこちら)
コンペの説明
今回のコンペは三回目となる鳥の鳴き声を検出するコンペで,特筆すべき点としてはハワイで絶滅の危機にある希少な鳥の鳴き声の検出が目的であることです. したがって,テストで対象となる鳥が主にハワイに生息する種21種に絞られていて,中にはtrainデータに1つのwavファイルしか存在しないものもありました.(trainデータは152種)
採点は,約60秒のwav5500個と,それぞれのwavでどの鳥を検出対象とするかが与えられます.参加者はそれに対して,検出対象の鳥が鳴いているか5秒単位でTrue/Falseを割り当てるコードを提出します. 評価方法は特殊なf1スコアで,正のクラスと負のクラスのスコアが等しくなるような重み付けをし,それを各鳥で算出,その後平均を取るようです.
実験と解法
結果から
今回は完全ソロで挑み,35位で銀メダルという結果に終わりました.序盤〜中盤は5位以内をキープしていただけに,なんとも言えない結果になってしまいました.
反省点は多々あるにしろかなり知見を得たコンペになったので,この記事でどんな実験をしてどんな知見を得たのかを放出したいと思います.
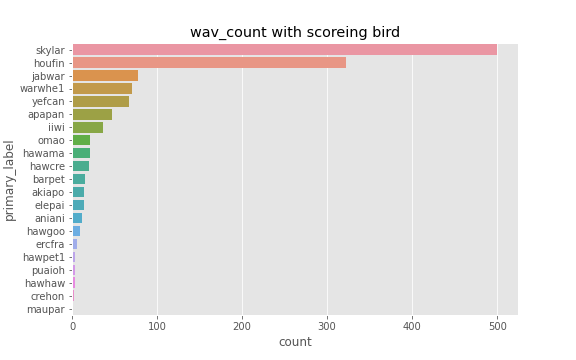
特徴量
昨今の音関連の深層学習モデルといえば,波形から画像を生成し特徴量とすることが多いです.その中でもよく用いられているのはメルスペクトログラムという画像形式なのですが,よりノイズに頑健な方法だったり,別のメルスペクトログラムからの変換方法を検討しました.
- pcen
Per-channel energy normalization(pcen)は,メルスペクトログラムのlogを取る代わりに,特殊な正規化を行います.この処理によりできた画像は,時間方向に変化量の多い周波数帯が強調され,変化の少ない周波数帯が抑制されたノイズの少ない画像になります.kaggle上のnotebookがとてもわかりやすいです.かなり期待して実験を行ったのですが,私の手元ではスコア向上にはつながりませんでした.
- linear spectrogram
そもそもメルスペクトログラムというものはスペクトログラムに対し,人間の耳に聞こえるような周波数帯を強調させるようなバイアスをかけて移動平均を取ったものです.(このどう移動平均を取るか決定づける行列は,フィルタバンクと呼ばれます.)このバイアスの種類により生成される画像が異なります.
本コンペでは,人間の耳に聞こえづらい周波数帯にも鳥の声の特徴が存在するのではないかと考え,バイアスなしの移動平均を用いた画像(勝手にlinear spectrogramとよんでいますが)を作りました.しかし,こちらも精度向上には至りませんでした.
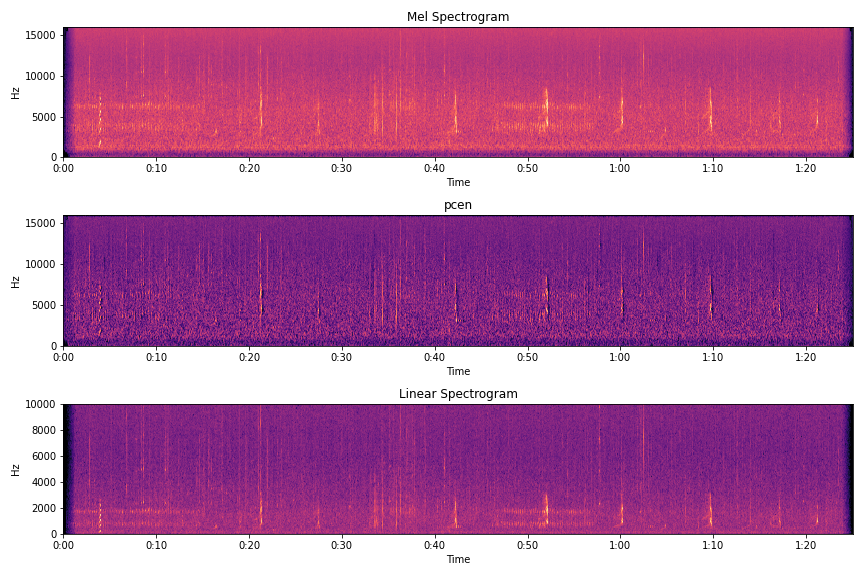
またこれはtipsなのですが,torchaudioを用いたメルスペクトログラムと,librosaを用いたメルスペクトログラムは,微妙に見た目が異なります.
同じ事象が,logを取る際にも発生します.これらの整合性のとれるコードをkaggle上にアップロードしますので,少々お待ちください→作成しました.
結局通常のメルスペクトログラムを用いるのが一番スコアが良かったです.1の案も2の案も,メルスペクトログラムと組み合わせたり,チャネル毎に用いる周波数帯をずらしたりしてみましたが,効果はありませんでした. ちなみに上位解法を見ると,CQTを用いて精度が向上したとの報告もありましたので,これはぜひ次回に活かしたいと思います.
モデル
今回,モデルは大きく3種類のアーキテクチャを検討/実装しました.
- PANNsベースのモデル
これはおなじみの方にはおなじみの,あらいさんモデルをベースにしたものです.詳細なアーキテクチャは本家ノートブックをどうぞ.クラス分類結果をフレーム単位で出力することができるため,Sound Event Detection(SED)タスクにはもってこいのモデルになっています.変更点としては,より時系列的な特徴を捉えられないかと,backboneに通した後のLinear層をLSTMに変更しています.これは若干の精度向上につながりました.
- STFT Transformer
これはCPMPが去年の鳥2コンペで考案したもので,ViTの入力にメルスペクトログラムを取れるようにしたモデルです.(本家実装)
特徴的なのは画像のパッチの作り方で,ある短い時間の全ての周波数帯が1つのパッチに入るように整形します.(メルスペクトログラムを縦に切るイメージ)メルスペクトログラムは通常の画像と違い縦方向は絶対的な値,横方向は時系列的な値になっています.この時間方向の関係性を捉えるためにパッチの作り方として,個人的にとてもしっくりくる手法です.
去年の鳥コンペ2ではCPMPがこれを用いて高いスコアを出していたのですが,私の実験ではPANNsのスコアを超えることは出来ませんでした.
- STFT Swin SEDモデル
これはコンペが始まった当初から実装したかったモデルで,上記STFT Transformerをベースとしつつ,フレームごとのクラス分類結果を出力できるようにしたモデルです.
上記STFT Transformerはフレーム単位でのクラス分類結果は出力できないため,STFT Transformerと同じようなアーキテクチャでよりSEDタスクに適した機構をつければスコア向上につながると考えました.今年の頭にSwin Transformerを用いたSEDモデルの論文が出ていたので,これを参考にパッチの埋め込み方をSTFT Transformerに変更したモデルを実装しました.
しかしこちらも,PANNsのスコアは超えることが出来ませんでした.
モデルに関しては,上位解法もほとんどPANNsベースだったように思います.Transformerは画像全体の特徴を見るのが得意とのことなので,単発的な鳥の声を分類するよりは定常的な音の分類などのほうが適したタスクなのかも知れません.
class imbalanceへの対応
学習データはかなり不均衡で,また評価対象の21種もかなり不均衡だったため,これの対処が肝だと考えました.したがって,この分野の調査にはけっこうな時間を費やしました.
- オーバーサンプリング
これに関しては以下の2種類スコアが向上した手法があります.
不均衡さを少しでも補正するため,wavの数が20を下回る種のwavに対し,オーバーサンプリングを行いました.またこの際,オーバーサンプリングしたものを過学習することを防ぐため,オーバーサンプリングを施したwavのみに対しaugmentationを強くかけました.これは少しスコアが向上しました.
Context-rich Minority Oversampling(CMO)とよばれる手法を用いました.これはCutMix時に少ないクラスをオーバーサンプリングするというとても単純明快な手法で,メルスペクトログラムに対して適用しても効果がありました.時間方向にのみCutMixするなど切り方を工夫してみましたが,単純なCutMixが一番良かったです.これは予想ですが,(マシンスペックが許せば)バッチサイズを大きくしたほうが各バッチで不均衡さが大きく出て,この効果がより現れる気がします.バッチサイズが小さいと,そもそも少ないクラスがバッチにないことが多かったり,多数派のクラスも1つしかサンプリングされない,なんてこともざらにありそうです(論文は128とかそれ以上の数を使っていました).
また,weightedrandomsamplerを用いて不均衡クラスを多めにサンプリングするということもやってみましたが,スコアは向上しませんでした.これは今思えばこれはCMOと相性が悪いように思います.
- lossの検討
focal loss以外のclass imbalanceに有効なlossもいくつか検討しました. CBLoss,ASL,IBLossと実装してみましたが,結局focal lossを超える精度は出せませんでした. 中でもepochの半分から決定境界付近にあるサンプルのweightを下げるIBlossと呼ばれる手法は,かなり期待を持って実装しましたが,CVスコアは伸びたもののPublicのスコアは向上しませんでした.
ローカルにおける評価方法
今回の評価方法は非常に掴みづらく,またCV/LBの相関が取れないということで,discussionでもスレが立っていました.私は以下のようなコードでCVスコアを計算していましたが,結局LBとの相関は全然取れませんでした.したがって,評価対象21クラスに対するこのメトリックスコアと,全152クラスのf1スコア(samples)を様々な閾値で計算し,それらが過半数程度上回っていたら提出するという作戦を取っていました.
def calc_tpr(true, pred, threshold): true = (true > 0.5) * 1 pred = (pred > threshold) * 1 tp = np.sum(true * pred) fn = np.sum(true * (1-pred)) tpr = tp / (tp + fn + 1e-6) return tpr def calc_tnr(true, pred, threshold): true = (true > 0.5) * 1 pred = (pred > threshold) * 1 tn = np.sum((1-true) * (1-pred)) fp = np.sum((1-true) * pred) tnr = tn / (tn + fp + 1e-6) return tnr class Metric(): def __init__(self): self.tgt_index = list(map(lambda x: CFG.target_columns.index(x), CFG.test_target_columns)) def calc_tgt_f1_score(self, gt_arr, pred_arr, th, epsilon=1e-9): scores = [] for i in self.tgt_index: a = list(gt_arr[:, i]) uni_, counts = np.unique(a, return_counts=True) # posi_weight = counts[0] / len(a) # nega_weight = counts[1] / len(a) posi_weight = 0.5 nega_weight = 0.5 tpr = calc_tpr(gt_arr[:, i], pred_arr[:, i], th) tnr = calc_tnr(gt_arr[:, i], pred_arr[:, i], th) score = posi_weight * tpr + nega_weight * tnr scores.append(score) return np.mean(scores)
推論処理
testはf1スコアベースの評価方法なので,True/Falseを決める閾値が重要になってきます.今回のコンペではかなり低めの閾値が適しているようでしたが,この原因は2つあると考えています.
- testデータではかなり正のクラスが少ないため,FPRが高くなったとしてもTPRを高めるのが大事なため
- 特に少ないクラスでは決定境界がかなり狭まっているため,閾値をかなり低くしないと正と判断されないため
二番目の理由については,逆に言えば多数派のクラスは閾値を高くしても正のクラスを検出できるのではないかと考え,最終的には閾値をクラスごとのデータ数を元に決定しました.例えば,一番学習データが多いクラスの閾値を0.3,一番少ないクラスの閾値を0.05に設定し,残りはデータ数を元に線形にスケールさせました.
またもう一つ工夫点があります.当初あるwav内に鳥が見つかったら,wav全体のそのクラスの予測確率を0.2上乗せするという後処理を行っていました.しかし,例えば閾値を0.05に設定している場合,0.2上乗せするとそのwav内は全ての秒数で対象のクラスの鳥が検出されていることになります.したがって,私の推論では評価対象21種中学習データが少ない(=閾値が0.2を超えない)19種の鳥において,音ファイル単位での予測しかしていません.wav内に鳥が見つかった際の後処理に関しては何パターンか検討しましたが,このスコアが一番良かったです.
その他後処理に関しても色々試行錯誤しましたが,スコア向上にはつながりませんでした.以下に例を上げます.
- 画像処理を用いてメルスペクトログラム中に単発音のようなものが表れているか検出.検出されない区間はどの鳥も鳴いていないと判定.
- 共起行列を用いて,一番予測確率が高い鳥と一緒に鳴いている可能性のある鳥の予測確率を高める
その他効かなかった実験
緯度経度をターゲットとしたモデルを作り,ハワイのみに生息する種においては,ハワイ以外の音と判定された時点で対象の鳥は鳴いてないと判定しました..
このモデル単体ではpublicで0.6くらい出ていたのですが,既存のモデルと組み合わせて精度は向上しませんでした.
pseudoラベルは,5foldのoofを用いて追加のsecondary_labelを追加したり逆に怪しいものを削ったりしてみましたが,
どれも効きませんでした.手作業でラベル付して精度が向上したとの報告をいくつか見たので,元のモデルの精度が足りなかったのかも知れません.
感想など
まずshakeについてです.私の予想では,大規模なshakeが起こると思っていました.publicのテストでは21クラス中半分のクラスも使われていないからです.鳥がprivateとpublicでクラスがまんべんなく分かれているのであればシェイクはしないかも知れませんが,publicにいない鳥の種が多いとなるとかなり揺れるだろうと踏んでいました.しかし,蓋を開けてみればそこまで揺れは大きくありませんでした.ならばなぜCVとLBの相関が取れなかったのかということですが,単純にホストとローカルの評価に用いるコードに違いがあったか,もしかすると音のモデルの評価にはどこで集音されたか,つまり周りの環境音がかなり寄与するのかも知れません.
続いて総括です.振り返ってみると,私はモデルの改良とインバランス対策の二点を重点的に対策していました.上位陣の解法と比較しても正直あまり違いはなかったので,金メダルを取れなかったのが悔しいです.進め方については今回のようなCV/LBで相関が取れないコンペでは,はやいうちに自分のスタンスを決めるべきだと痛感しました.例えばTrust CVで行くのか,とりあえず全実験を提出してTrust LBで行くのか…などです.(そもそもこういうコンペには参加しない,という手もあります)コンペ終盤は,相関は取れないし最後1ヶ月まったくスコアを伸ばすことが出来ないし,ソロなので相談できる人もいないしで,今までで一番精神的にきつかったです.しかしkaggleのコツは狙ったメダルが取れなかったくらいで諦めないことだと思っていますので,これからもがんばります.
ちなみにコンペ自体は,ホストのモデルが結局最強でしかもこれの使用許可が終了二日前におりるといったこともあり(参考),2022年ク◯コンペにノミネートされそうですが,まあ学びは多かったのでOKです(ほんとか?)
最後は感想超えて反省超えて呪詛のようになってしまいましたが,以上で振り返りとしたいと思います.読んでくださった方ありがとうございました.
kaggle 圧力コンペ 振り返り
はじめましての人ははじめまして.普段sqrt4kaidoという名前でkaggleのコンペなどに参加しています.
本記事では,先日まで行われていたGoogle Brain - Ventilator Pressure Prediction(通称: 圧力コンペ)の振り返りを行いたいと思います.
今回はちょっと趣向を変えて,概要,反省を折り込みながらのコンペ期間の流れ,そして結果という順で記載しようと思います.
コンペ概要
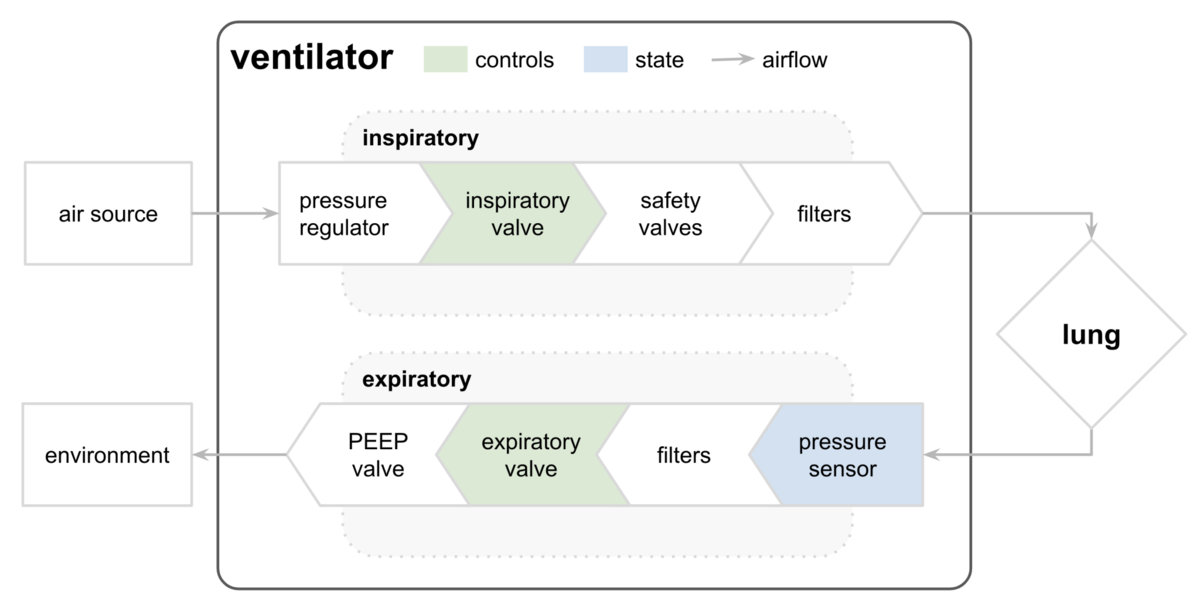
人工呼吸器のシミュレーションとして,ある時刻における肺内の圧力を計算するコンペです.
人工呼吸器は吸気フェーズと呼気フェーズとに分かれており,弁の開き具合や肺の硬さなどの条件により,肺内の圧力が変わってきます.
評価指標は単純なMAEですが,吸気段階のみが評価に使われます.
データ
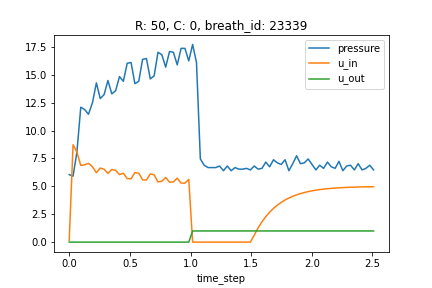
データは以下のカラムが用意されたテーブルデータでした.カラムの数としては少なく,また時系列性を持っていました.
- time_step…データ取得時間です.
- u_in…吸気電磁弁の制御入力.これは空気を肺へ送る弁の開き具合に相当する量で,0~100の範囲で表されます.
- u_out…呼気を司る弁の値で,0で閉まっている状態,1で開いている状態を表しています.今回のコンペでは,u_out=0の際の圧力が評価対象です.
- R…RはResistanceの略で,肺への空気の入れにくさを表しています(肺へ通ずるストローの太さのイメージ).本コンペでのRは5, 20, 50の3種類であり,50が一番抵抗が高いです.
- C…CはComplianceの略で,肺自体の硬さのような指標です.この数値が高いほど,肺は膨らみやすいです.本コンペでのCは10, 20, 50の3種類です.
- pressure…今回予測するターゲットです.time_stamp時点での気道内圧(cmH2O)です.測定機器の分解能から,測定値は完全な連続値ではなく,950種類の離散的な値となっていました.
コンペ期間中の流れ
前半
今回は,かなり初期段階からチームを組んで戦いました.
始めはpytorchを用いた回帰予測タスクとして取り組んでいましたが,他にも悩まれていた方が多くいらっしゃったように,pytorchで中々kerasと同程度の性能が出ませんでした.
kerasとpytorchのLSTMにおける初期化の違い等が話題になっており,自分もなかなかkerasの公開ノートブックのスコアを越せず,チューニングにかなり時間をかけてしまいました.
中盤
中盤は,回帰ではなく950クラスのクラス分類タスクとして解く公開ノートブックを試したところ伸びしろがありそう&早く収束しそうだったため,
回帰はチームメンバーに任せて,私はクラス分類モデルを深堀していくことにしました.
中盤でスコア上昇に寄与した要因はだいたい以下のとおりです.
- 加重平均での予測に変更
- todaさんのカスタムloss + 加重平均のMAE loss
- u_inのsqrt
80epochでまあまあの精度が出せるモデルを作ることが出来たので,実験をスピードアップして行うことが出来ていました.(チューニングも引き続き行っていました.)
気づいたこととして,R=50のスコアが悪く,分析してみると細かい動きは当てれているものの,平行に大きくずれるbreath_idがいくつか見られることがありました.
圧力はうまく可視化をすると隠れた何パターンかの設定値が見えてきており,おそらくその予測を間違っているようでした.
と,ここまではよかったのですが,ではこれをどう補正するかがなかなか思いつかず,苦戦しました.おそらくクラスタリングやknnを用いた特徴が効くのではないかと思いましたが,うまく特徴化することが出来ませんでした…
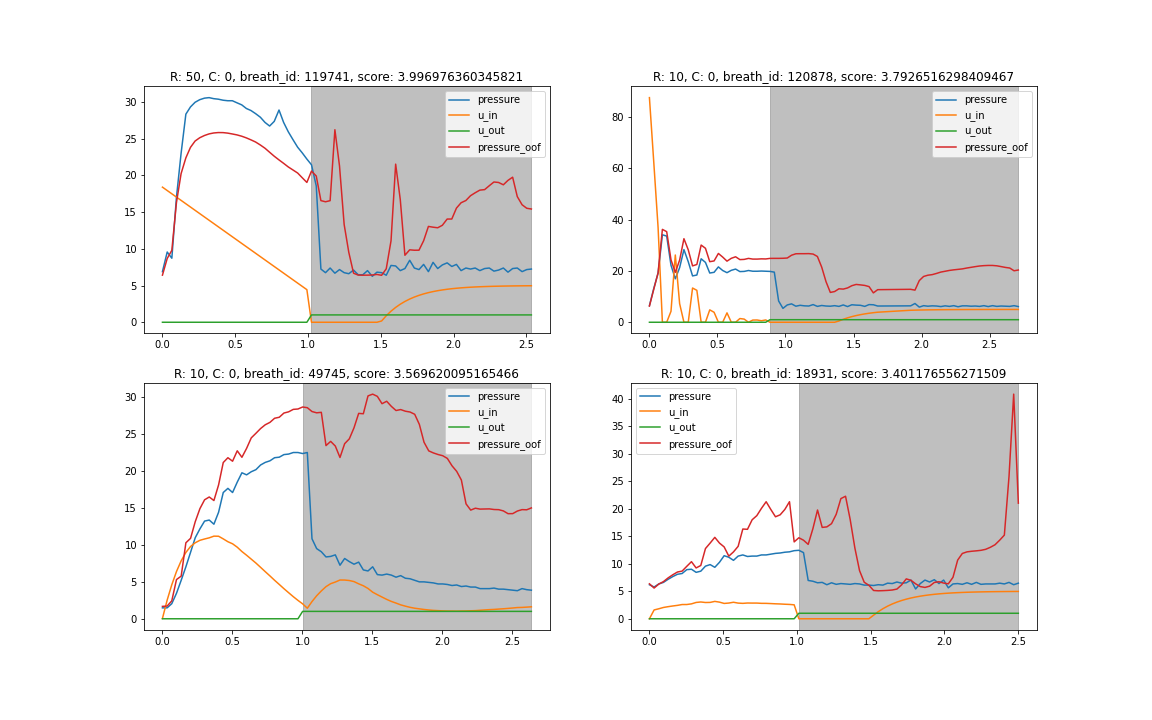
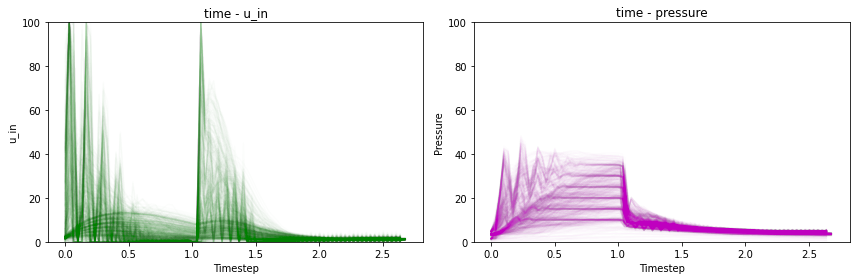
結局,u_inの大きい動きを入れることで何とかならないかと思いローパスを掛けたu_inと,それを用いた特徴量を入れてみました.結果,これは精度向上には繋がったのですが,平行ずれはとれませんでした.
ソリューションを見ると,やはりu_inが近い距離のデータを用いた特徴を効かせていたチームもありました.
また,チームの方がこの段階から積極的にアンサンブルを行っていたため,チームとしてのスコアもどんどん伸びていきました.
アンサンブルでは,シンプルに中央値(MAEの場合,平均より中央値のほうが良い)を取ったものか,optunaで重みを最適化して中央値を取ったものを用いていました.
終盤
終盤では,LSTM + Transformerのモデルに変更しました.また,fold数を増やすと顕著にスコアに効いたということで,
結局,私のシングルモデルのベストは20foldでCV: 0.1344 LB: 0.1187 でした.
しかし,金圏付近の他チームの伸びがすごく,残り一週間時点で20位付近まで下がってしまったため,私達も何かあと一つ強みを発見しないと金メダルは取れないと試行錯誤していました.(また何かに気づいてかなり高いスコアを出しているチームもありました)
ポストプロセスとして,cosine類似度を用いてu_inの類似度がtrainデータととても高いtestのデータがあったら,trainデータの圧力値をtestに用いる作戦を考えました.
これは特に,u_inが全て0という特殊なbreath_idの予測を救済しようと考えたためです.しかし,あまりうまく行きませんでした.
結局,スタッキングがとても効きそうなことをチームメンバーが発見し,残り数日で一斉にみんなでスタッキングモデルを作成しました.
lgbm,Xgboost,mlpなどが寄与していたと思います.
スタッキングは二段目まで行いました.一段目と比べて精度が向上すれば三段目まで行おうとしましたが,思ったより伸びなかったため,
最終的には一段目のスタッキングモデルの重み最適化した中央値アンサンブルと,二段目のスタッキングの重み最適化した中央値アンサンブルを提出しました.
結果と反省
結果,17位で金メダルにはわずかに届きませんでした.残念…

終了後に世間を賑わせていたリークについてですが,これはu_inが測定された圧力値によりPID制御されていることから,pressureを代数計算で出せるというものでした.
1位はtestデータの66%を完璧に当てることが出来ていたようです.
[#1 Solution] PID Controller Matching (V1) | Kaggle
進め方的な反省としては,pytorchで精度が出にくかったの少しありますが,やはりチューニングに時間を掛けすぎたかなと思っています.
普段こんなにハイパラチューニングに時間をかけることはないのですが,もともと精度の高い争いになっていたためか(MAEで0.1台って普通にすごい),
この辺の設定値がスコアに直結してくる印象でした.
最終的には80epochで回せるモデルを作れたのは良かったのですが,もっとホストの論文やリポジトリに目を向けるべきでした(読んでいたとして,リークに気づけたかはアレ) .
データがどう作られているかはデータの特性を掴み,ホストの論文をちゃんと読めばわかることでしたので,きちんと取り組まなかったことが悔やまれます.
まとめ
今回のコンペはリークに気づけたチームが大きく精度を伸ばす結果となりましたが,リークを用いなかったチームも金圏に複数あったのも事実ですので,悔しいです.
その一方で,シングルモデルの精度では,金メダルのチームに負けずとも劣らずの性能を出せていたと思うので,そこはちょっと自信になりました. (とは言っても,まだまだですが)
終盤は他チームのスコア変動がとても激しく,精神的負荷が半端じゃなかったです.チームメンバーがいなければその中で戦えなかったと思うので本当に感謝です.
金メダルを取るのは本当にむずかしいですが,今後も挑み続けていきたいと思います.
自分のベストモデルのコードです,ご参考までに.
kaggle MLBコンペ 振り返り
はじめましての方ははじめまして. 普段,sqrt4kaidoという名前でkaggle等のコンペに参戦しています.
先日まで,MLB Player Digital Engagement Forecastingというコンペ(以降,省略のためMLBコンペと呼びます)に参加していました.
今現在も評価フェーズ中のため最終的な順位は出ていないのですが,MLBコンペにおける概要,重要なポイント等を振り返りたいと思います.
思いのままに記述したらまとまりのない文章になってしまいましたが,ご理解ください…
MLBコンペ 概要
本コンペは,期間は2ヶ月と若干短めのコンペで,
野球のメジャーリーガー選手(MLB選手)のサブセットについて4つの異なるエンゲージメント指標(target1~target4)を予測するという時系列タスクでした.
ある試合のデータ(勝ち負けやスコア,各プレーヤーのパフォーマンス)やオールスターなどの受賞,移籍情報といった情報から,次の日のエンゲージメントを予測します.
評価指標は4つのtargetのMAEの平均です.
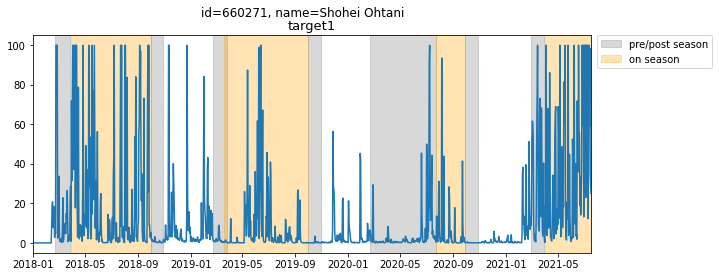
例えば,大谷翔平選手の例では,特に今シーズンのエンゲージメントがとても高いことを確認できます.
(提供されるエンゲージメントは0~100の間にスケールされています.)
本コンペは学習フェーズと評価フェーズに分かれています.学習フェーズでは2018/01~2021/04までの学習データが与えられ,2021/05のtargetを用いてtestが行われ,LBが更新されます.
さらに学習フェーズ終盤には,学習データが更新され,7/17日までのデータが使えるようになります.更新後のデータを使うかどうかは各自の自由です.
評価フェーズはコンペ終了後8/1~9/15まで続きます.評価に使われる具体的な日付については,アナウンスされていません.
ただ,どうやらLBは定期的に更新されるようです.
最終的な順位は,評価フェーズ終了の9/15日に決定されます.
重要ポイント
私が今回のコンペで肝だと感じたのは以下の三点です.
学習データの種類の多さ
学習に用いることのできるデータには,playerの情報や移籍情報など,様々なcsvファイルがありますが,特徴的なのはtrain.csvでした.
本コンペのtrain.csvの中身は,一行が一日のデータになっています.カラムは,試合の情報や,targetなどです.
ですが,各セルにはjsonの形式で情報が入っているため,これを展開する必要が有りました.
学習データ全体を俯瞰できるER図
train.csvを展開してみると,上記ER図の通り,使用できるcsv,そしてカラムの数がとても多いコンペであることが確認できます.カラムを一通り眺めるだけでもかなりの時間と気力を要したと思います.
したがって,これらの情報をどう使うか工夫が必要でした.
実際,私個人としては,「events」という各試合の情報に関するカラムに関して,あまり深堀りすることが出来ませんでした.
評価方法
本コンペは,kaggleのTime-series APIを用いて提出します.
通常のコンペのように予測値を格納したcsvファイルを提出するのではなく,このAPIを用いて動作するコード自体を提出します.
Time-series APIではイテレータを用いてtestデータが提供されるのですが,一回のループでは,上記train.csvの一行のような一日分のデータのみが提供されます.
したがって実際に予測を行うためには,jsonを展開し,整形し,予測するという作業をループの中で行う必要が有りました.
過去のコンペ等使用したことのある方にとっては馴染みがあるかも知れませんが,自分も含め初めての方にとっては,学習時のコードをそのまま推論に使えないため,
エラーが出ないか,正しく予測が行われているか見極める難易度が高かったと思います.
(実際,体感でDiscussionの約半数が,Time-series APIを用いた提出時のエラーについての相談で埋まっていました.)
lag特徴量
コンペ中の公開ノートブックの中で,targetのlagを特徴量とするとかなりスコアが改善されることがわかっていました. しかし,
- 評価フェーズ中に,前の日の正解が渡されない
- 評価において,連続性が保証されていないとアナウンスされていた
以上等の点から,この特徴をどう使うかを試行錯誤していたチームが(おそらく)多いのではないかと思います.
すでに公開されている解法の中では,例えば
- 前の試合結果や,試合の情報といった,targetではない特徴のlagを組み合わせる 参照
- gapを設け,評価フェーズより前のlagのみを用いる.gapは複数パターン設け,推論日によってモデルを切り替える.参照
などといった工夫が見られました.
私の解法と,チームの提出モデル
今回私は,makabeさんとteaさんよりチームにお誘いいただき,途中から3人チームで戦いました.
私個人の解法の特徴としては,lagを使っていないことです.
モデルはLGBMを用いました.主な効いた特徴は以下のとおりです.
- validの月のtarget統計量(validationにリークしているが,testでも効いたので採用)
- シーズン中だけのデータに絞る(オフシーズンのデータは全て使わない)
- 各プレイヤーの,前に試合を行ってからの日数
- optunaのハイパラ調整
- チームの順位
学習データ更新前で,シングルモデルのスコアは1.3146がベストでした.
また,validationは2021/4,5,6月で行い,最終subには2021/6月をvalidationにしたモデルのみを用いました(7月は他の月とはtargetに違った傾向が出ていたため,用いませんでした).
アンサンブルは,seedの異なるモデル2つと,全playerを用いたモデルの計3つを用いました.
代表的な効かなかった特徴としては
- 試合を行ったデータと行わないデータで別々のモデルを作る.
試合を行っていないデータは全体的にtargetが低いことが確認できました.したがって,試合のあるデータとは違う分布を持っていると判断し,モデルを分けていました.
学習データ更新前までは効果があったのですが,学習データ更新後はなぜか効かなくなってしまったため,最終subには用いませんでした.
(元々target1,2,3,4で別々のモデルを使っていたので,さらに試合のあるなしで分けると管理が大変,というのもありました)
- スケール
今回のtargetは0~100にスケールされていますが,それがどうやら日にちごとにmaxスケーリングされているようだというディスカッションがありました.
そこで,スケールを戻して学習を行ってみたところ,CVの結果は改善しましたが,実際にtestデータに適用するとなると,
maxの予測がずれると,間違ったスケーリングが行われてしまうため一日のデータ全てがずれることになってしまい,スコアは悪化してしまいました.
前の年の同じ月の平均に合わせるようにスケーリングするなどの方法も試したが,精度は改善しませんでした.
チームの他2名はlagを用いていたため,lagをどう使うかに関してはたくさん議論を重ねました.
最終的には,3人のモデルのアンサンブルなのですが,
- lagを用いていないsub
- 前半20日のみlagを用い,後半はlagを用いていないsub
の2つを提出しました.
ちょっと苦労話
これは余談であり,言い訳です…
lagを用いたモデルについては,個人的にモデルを工夫する以前に頭を抱える問題が有りました.
今回のコンペは,終盤までホスト側が評価フェーズの連続性を仮定しないでくださいと忠告を出していました.
つまり,評価日も中途半端な日にちから始まるかも知れないし,間に穴があるかも知れないということです.
これだと,lag関連の特徴,また累積系の特徴など,時系列性を持つ特徴が一切使えないことになります.
自分はこのような状況の中で,lagを使うという方針で行くとはなれませんでした…
(このあたりの評価フェーズに関する情報がかなり曖昧かつ点在していたところも,本コンペの難しさだったのかも知れません.)
実際,ホストから
- 評価フェーズは8/1からはじまるよ
- 評価日が途中から始まる場合でも,8/1からの再実行を行うよ
と明示されたのは,かなりコンペ終盤になってからです.
これは言い換えると,評価フェーズも連続的に行うことになるので,何も変更がなければですが,評価フェーズでもlagが機能すると思います.
(連続性が仮定されなくても機能するモデルを作れよと言われたら,ぐうの音も出ません…)
まとめ
というわけで,一見普通のテーブルデータコンペでしたが,
- 評価フェーズに関する情報がかなり曖昧であった
- Time-series API
- カラムの多さ
などから,なかなか難易度の高いコンペだったのではないでしょうか.
また,私はドメイン知識が殆どなかったため,チームのお二人にかなり教えていただきました.
さらに,lag周りの方針についても建設的に話し合うことができ,本当にとても感謝しています.
9/15日までまだまだあるので,まずコードがエラーを吐かずにうごきますように.
そして,いいスコアが出るよう祈りつつ,待っていようと思います.
↓学習データが更新される前の記念写真
(更新後は,publicのtestに使用するデータに変更はなかったため,リークやら答えそのまま出すsubやらでLBがぶっ壊れてしまいました)
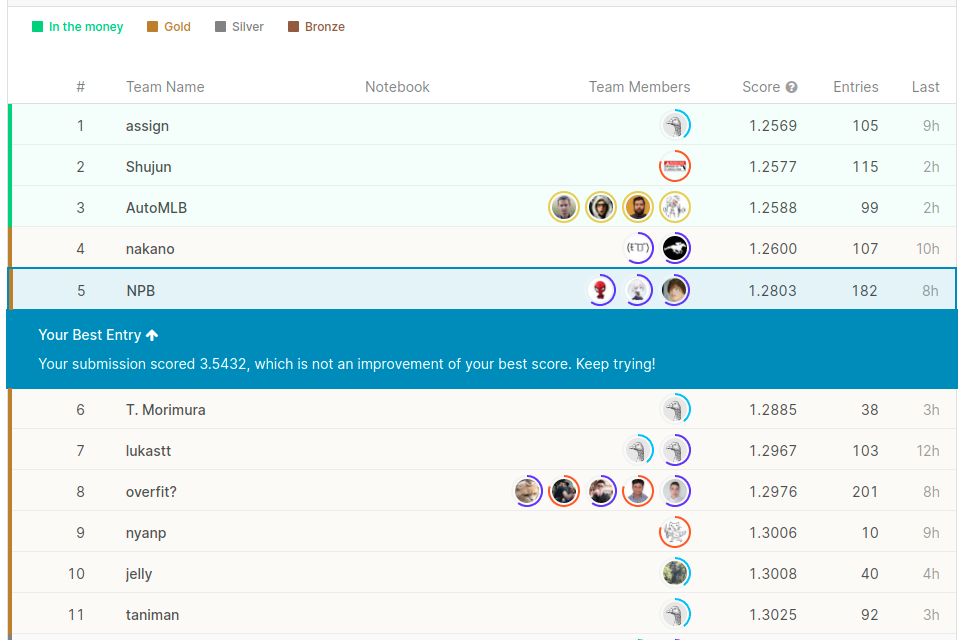
9/15 追記
結果が出ましたので,追記です.
最終的には8/31日までのデータによりスコアが算出され,6位で金メダルを取ることが出来ました!
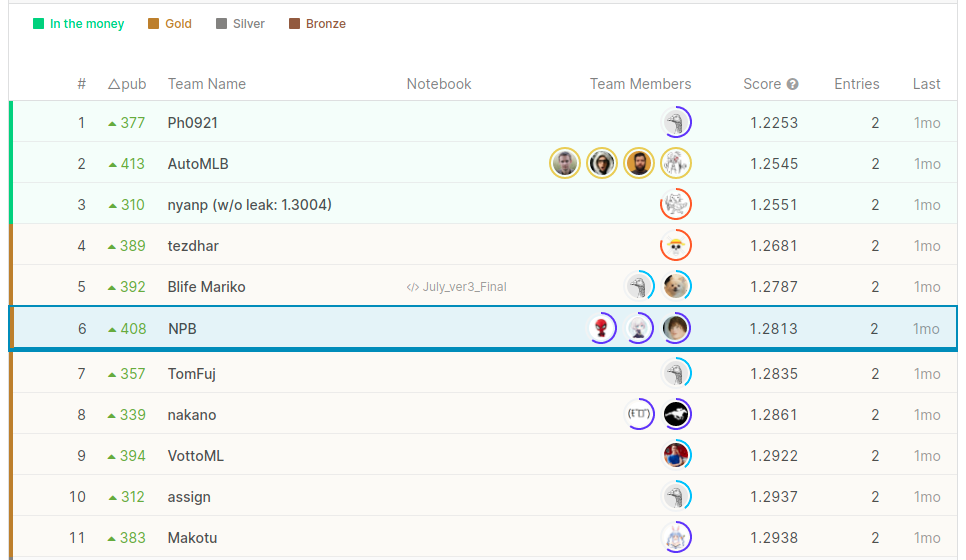
途中,何回か順位がアップデートされていたのですが,3位→8位と推移していたので
金メダル圏内に残れるかそわそわしていましたが,生き残れてよかったです.
弊チームの解法は下記に載せています. www.kaggle.com
マスターが見えてきましたが,慢心せずこれからも頑張っていこうと思います.