kaggle MLBコンペ 振り返り
はじめましての方ははじめまして. 普段,sqrt4kaidoという名前でkaggle等のコンペに参戦しています.
先日まで,MLB Player Digital Engagement Forecastingというコンペ(以降,省略のためMLBコンペと呼びます)に参加していました.
今現在も評価フェーズ中のため最終的な順位は出ていないのですが,MLBコンペにおける概要,重要なポイント等を振り返りたいと思います.
思いのままに記述したらまとまりのない文章になってしまいましたが,ご理解ください…
MLBコンペ 概要
本コンペは,期間は2ヶ月と若干短めのコンペで,
野球のメジャーリーガー選手(MLB選手)のサブセットについて4つの異なるエンゲージメント指標(target1~target4)を予測するという時系列タスクでした.
ある試合のデータ(勝ち負けやスコア,各プレーヤーのパフォーマンス)やオールスターなどの受賞,移籍情報といった情報から,次の日のエンゲージメントを予測します.
評価指標は4つのtargetのMAEの平均です.
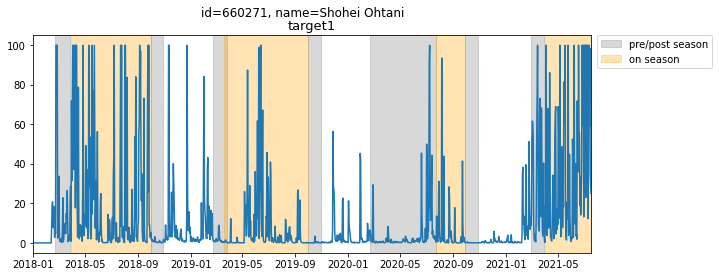
例えば,大谷翔平選手の例では,特に今シーズンのエンゲージメントがとても高いことを確認できます.
(提供されるエンゲージメントは0~100の間にスケールされています.)
本コンペは学習フェーズと評価フェーズに分かれています.学習フェーズでは2018/01~2021/04までの学習データが与えられ,2021/05のtargetを用いてtestが行われ,LBが更新されます.
さらに学習フェーズ終盤には,学習データが更新され,7/17日までのデータが使えるようになります.更新後のデータを使うかどうかは各自の自由です.
評価フェーズはコンペ終了後8/1~9/15まで続きます.評価に使われる具体的な日付については,アナウンスされていません.
ただ,どうやらLBは定期的に更新されるようです.
最終的な順位は,評価フェーズ終了の9/15日に決定されます.
重要ポイント
私が今回のコンペで肝だと感じたのは以下の三点です.
学習データの種類の多さ
学習に用いることのできるデータには,playerの情報や移籍情報など,様々なcsvファイルがありますが,特徴的なのはtrain.csvでした.
本コンペのtrain.csvの中身は,一行が一日のデータになっています.カラムは,試合の情報や,targetなどです.
ですが,各セルにはjsonの形式で情報が入っているため,これを展開する必要が有りました.
学習データ全体を俯瞰できるER図
train.csvを展開してみると,上記ER図の通り,使用できるcsv,そしてカラムの数がとても多いコンペであることが確認できます.カラムを一通り眺めるだけでもかなりの時間と気力を要したと思います.
したがって,これらの情報をどう使うか工夫が必要でした.
実際,私個人としては,「events」という各試合の情報に関するカラムに関して,あまり深堀りすることが出来ませんでした.
評価方法
本コンペは,kaggleのTime-series APIを用いて提出します.
通常のコンペのように予測値を格納したcsvファイルを提出するのではなく,このAPIを用いて動作するコード自体を提出します.
Time-series APIではイテレータを用いてtestデータが提供されるのですが,一回のループでは,上記train.csvの一行のような一日分のデータのみが提供されます.
したがって実際に予測を行うためには,jsonを展開し,整形し,予測するという作業をループの中で行う必要が有りました.
過去のコンペ等使用したことのある方にとっては馴染みがあるかも知れませんが,自分も含め初めての方にとっては,学習時のコードをそのまま推論に使えないため,
エラーが出ないか,正しく予測が行われているか見極める難易度が高かったと思います.
(実際,体感でDiscussionの約半数が,Time-series APIを用いた提出時のエラーについての相談で埋まっていました.)
lag特徴量
コンペ中の公開ノートブックの中で,targetのlagを特徴量とするとかなりスコアが改善されることがわかっていました. しかし,
- 評価フェーズ中に,前の日の正解が渡されない
- 評価において,連続性が保証されていないとアナウンスされていた
以上等の点から,この特徴をどう使うかを試行錯誤していたチームが(おそらく)多いのではないかと思います.
すでに公開されている解法の中では,例えば
- 前の試合結果や,試合の情報といった,targetではない特徴のlagを組み合わせる 参照
- gapを設け,評価フェーズより前のlagのみを用いる.gapは複数パターン設け,推論日によってモデルを切り替える.参照
などといった工夫が見られました.
私の解法と,チームの提出モデル
今回私は,makabeさんとteaさんよりチームにお誘いいただき,途中から3人チームで戦いました.
私個人の解法の特徴としては,lagを使っていないことです.
モデルはLGBMを用いました.主な効いた特徴は以下のとおりです.
- validの月のtarget統計量(validationにリークしているが,testでも効いたので採用)
- シーズン中だけのデータに絞る(オフシーズンのデータは全て使わない)
- 各プレイヤーの,前に試合を行ってからの日数
- optunaのハイパラ調整
- チームの順位
学習データ更新前で,シングルモデルのスコアは1.3146がベストでした.
また,validationは2021/4,5,6月で行い,最終subには2021/6月をvalidationにしたモデルのみを用いました(7月は他の月とはtargetに違った傾向が出ていたため,用いませんでした).
アンサンブルは,seedの異なるモデル2つと,全playerを用いたモデルの計3つを用いました.
代表的な効かなかった特徴としては
- 試合を行ったデータと行わないデータで別々のモデルを作る.
試合を行っていないデータは全体的にtargetが低いことが確認できました.したがって,試合のあるデータとは違う分布を持っていると判断し,モデルを分けていました.
学習データ更新前までは効果があったのですが,学習データ更新後はなぜか効かなくなってしまったため,最終subには用いませんでした.
(元々target1,2,3,4で別々のモデルを使っていたので,さらに試合のあるなしで分けると管理が大変,というのもありました)
- スケール
今回のtargetは0~100にスケールされていますが,それがどうやら日にちごとにmaxスケーリングされているようだというディスカッションがありました.
そこで,スケールを戻して学習を行ってみたところ,CVの結果は改善しましたが,実際にtestデータに適用するとなると,
maxの予測がずれると,間違ったスケーリングが行われてしまうため一日のデータ全てがずれることになってしまい,スコアは悪化してしまいました.
前の年の同じ月の平均に合わせるようにスケーリングするなどの方法も試したが,精度は改善しませんでした.
チームの他2名はlagを用いていたため,lagをどう使うかに関してはたくさん議論を重ねました.
最終的には,3人のモデルのアンサンブルなのですが,
- lagを用いていないsub
- 前半20日のみlagを用い,後半はlagを用いていないsub
の2つを提出しました.
ちょっと苦労話
これは余談であり,言い訳です…
lagを用いたモデルについては,個人的にモデルを工夫する以前に頭を抱える問題が有りました.
今回のコンペは,終盤までホスト側が評価フェーズの連続性を仮定しないでくださいと忠告を出していました.
つまり,評価日も中途半端な日にちから始まるかも知れないし,間に穴があるかも知れないということです.
これだと,lag関連の特徴,また累積系の特徴など,時系列性を持つ特徴が一切使えないことになります.
自分はこのような状況の中で,lagを使うという方針で行くとはなれませんでした…
(このあたりの評価フェーズに関する情報がかなり曖昧かつ点在していたところも,本コンペの難しさだったのかも知れません.)
実際,ホストから
- 評価フェーズは8/1からはじまるよ
- 評価日が途中から始まる場合でも,8/1からの再実行を行うよ
と明示されたのは,かなりコンペ終盤になってからです.
これは言い換えると,評価フェーズも連続的に行うことになるので,何も変更がなければですが,評価フェーズでもlagが機能すると思います.
(連続性が仮定されなくても機能するモデルを作れよと言われたら,ぐうの音も出ません…)
lagを使った人たちは,この発言を引き出すことにつながったディスカッションを立てた私に一日一万回感謝してほしいです.(うそです)
まとめ
というわけで,一見普通のテーブルデータコンペでしたが,
- 評価フェーズに関する情報がかなり曖昧であった
- Time-series API
- カラムの多さ
などから,なかなか難易度の高いコンペだったのではないでしょうか.
また,私はドメイン知識が殆どなかったため,チームのお二人にかなり教えていただきました.
さらに,lag周りの方針についても建設的に話し合うことができ,本当にとても感謝しています.
9/15日までまだまだあるので,まずコードがエラーを吐かずにうごきますように.
そして,いいスコアが出るよう祈りつつ,待っていようと思います.
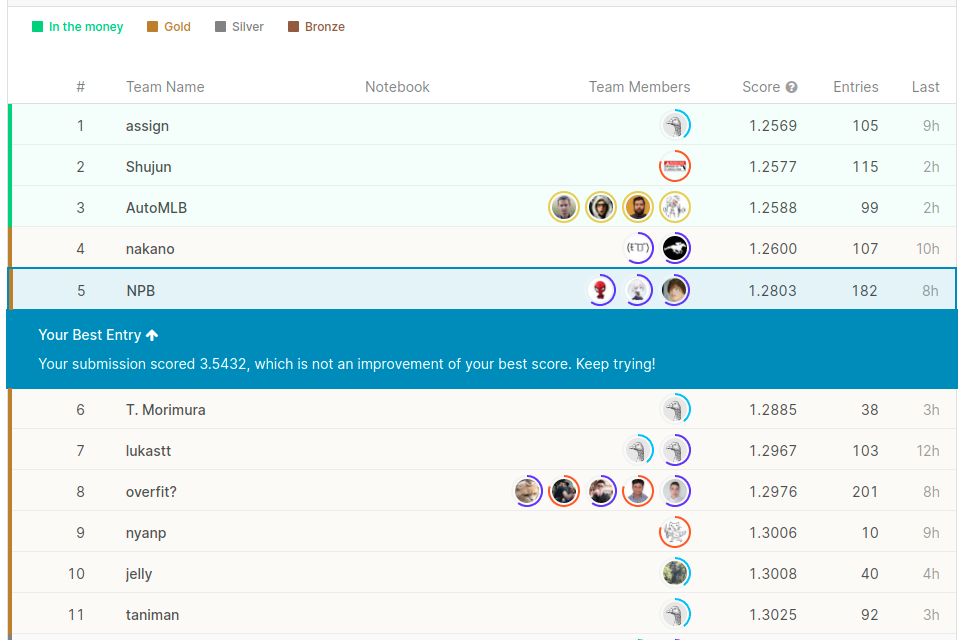
↓学習データが更新される前の記念写真
(更新後は,publicのtestに使用するデータに変更はなかったため,リークやら答えそのまま出すsubやらでLBがぶっ壊れてしまいました)
9/15 追記
結果が出ましたので,追記です.
最終的には8/31日までのデータによりスコアが算出され,6位で金メダルを取ることが出来ました!
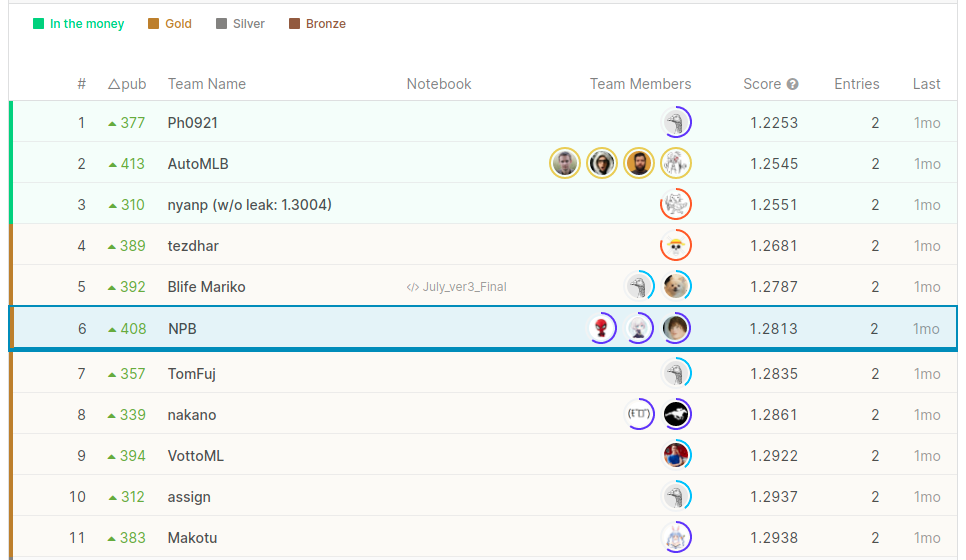
途中,何回か順位がアップデートされていたのですが,3位→8位と推移していたので
金メダル圏内に残れるかそわそわしていましたが,生き残れてよかったです.
弊チームの解法は下記に載せています. www.kaggle.com
マスターが見えてきましたが,慢心せずこれからも頑張っていこうと思います.