G2Netコンペ2023 振り返り
はじめましての人ははじめまして.普段sqrt4kaidoという名前でkaggleのコンペなどに参加しています.本記事では,先日まで行われていたG2Netの振り返りを行いたいと思います.
概要
シミュレートされた重力波干渉計のデータから、連続重力波信号が含まれているかを予測するタスクでした。連続重量波信号はとても微弱であり、ノイズの中から如何にこれを見つけるかが焦点となっていました。それぞれのサンプルにはLIGO Hanford(H1) と LIGO Livingston(L1)から観測された信号をSTFTしたデータ(スペクトログラム)と時間、周波数といったメタデータが一緒くたに入っていました。

データ数は
- train…603個
- test…7975個
と、提供されたtrainデータがとても少ないのが特徴的でした。その代わりホストからデータ生成を行うことができるAPIが提供され、 必要に応じて自分達で追加の学習データセットを作ることができました。
結果
今回私はtattakaさんと2人チームで参加し、Public88位、Privateは17位という結果に終わりました。
我々はCNNを中心としたアプローチに取り組んでいましたが、 蓋を開けてみると、上位の方はアルゴリズムベースの解法を採用していました。
解法紹介
私が取り組んだ解法について説明します。前述したようにCNNをベースとし、データ生成や前処理などを工夫しました。
学習データ生成
色々彷徨いましたが、最終的にはノイズのほとんどない純粋なシグナルとノイズを事前に生成しておいて、学習中にオンラインで足し合わせる方法に落ち着きました。
ノイズ入りのシグナルをあらかじめ生成するのに比べ、より多様なノイズ+シグナルの組み合わせを学習できると考えたためです。
ノイズ生成はこちらのノートブックを参考に、テストのノイズを模倣するようなデータを作成しました。足し合わせる際はスペクトルのパワーを用いたSNRベースの加算を行うことで、どのシグナル/ノイズの組み合わせでも同じような見た目のシグナルの強さになるよう調整しました。
データ数は正例1000個、負例2000個です。
validationには、別で生成したノイズとノイズ入りのシグナルを用い、どのモデルでも同じ評価ができるようにしました。
前処理
少し脱線しますが、コンペ中は、validationでは良いスコアが出ているのにも関わらずtestで同じようなスコアが出ないことに散々苦しみました。
従って、testデータを確認し、生成データには存在しないがtestデータには存在する特徴を細分化し、対策しようとしました。
- 非定常ノイズ…testデータの20%ほどには、時間軸方向に非定常なノイズが含まれていました。
- 観測失敗?データ…ほとんどノイズや信号が観測されていないようなサンプルがありました。
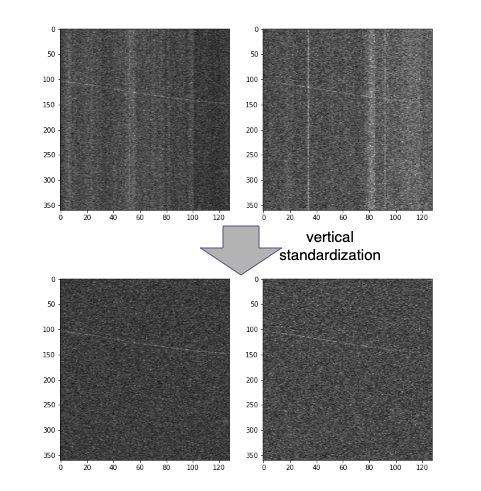
前処理に話を戻すと、この段階では上記1の問題に対して対策を行いました。具体的には、標準化を縦方向に行うことで非定常ノイズのみを消去することができました。
また、cutout, hflip, vflip, hvflipといったaugmentationを行っています。
シグナルやノイズを長めに生成しておいて、学習時にcutoutするaugmentationも効きました。
モデル
モデルに突っ込む前のスペクトログラムにはOR mixupをかけました。
モデルは基本的にtf_efficientnet_b7_nsを用いました。アンサンブルとして、近いスコアが出ていたPANNSアーキテクチャのモデルも用いました。シグナルは全て左端から右端にかけて存在していたため、局所的な特徴に強いCNNよりTransformer系のモデルの方が強いのではないかと実験を行いましたが、うまくいきませんでした。
予測
testデータの予測時には、ttaを行っています、中身としては、cutout, hflip, vflip, hvflip, ch_swapの5つです。また、学習時と同じようにtestのシグナルもcutoutしました。これもかなり効きました。
前処理で説明した「2. 観測失敗?データ」に対してもここで対策を行いました。観測されていないデータは、ほとんどの場合L1かH1のどちらか片方のみでした。従って、
- 前処理をかけた画像の分布から尖度を測定
- L1とH1で乖離が見られるサンプルを抽出
- 2で該当したサンプルは、正しく観測されている方のチャンネルのみを予測に用いる
以上の順番で対策を行いました。
その他工夫
pseudoラベルは、そのまま用いても精度が向上しませんでした。(ソフトラベル、ハードラベル共に) そこでnoisy studentを使ってみたところ、精度が向上しました。OR mixupもそうですが、SETIコンペのアイデアが複数有用でした。
また、アンサンブルはLazy Ensembling Algorithmを用いて相関の高いsubのweightを小さくしました。(これはtattakaさんのナイスアイデアです!)
感想、上位解法との差分
前述したように、上位の方はCNNなどの機械学習手法ではなく、信号を探索するアルゴリズムを用いていました。探索のアルゴリズムは様々ですが、テンプレートとなる信号を用意しマッチングをとることで高スコアを取ることができたようでした。
コンペを進めていく中でも、アルゴリズム系のコンペや競プロも強い方が上位にいたので、アルゴリズムベースのアプローチが強いんだろうなという予想はついていました。じゃあやれよ!!!という話ですが、CV系の方も上位にいたので、我々はそちらを突き詰めていくことにしました。一応ビタビアルゴリズムは試しましたが、SNRの高いシグナルしか検出できなかったため、採用しませんでした。
深層学習を用いる場合、
- できるだけ多様なシグナルを学習させる
- testデータ特有のノイズへの対策
上記2点が本コンペで良いスコアを出すために重要な点だったと考えています。特に2に関しては上位の方と差が出てしまったと感じていて、例えば上位の方はtestで観察されるランダムウォークやラインノイズを混入させていたりしていました。また、testのノイズが使い回されていることを発見し、差分を取ることで非定常ノイズをほとんど消したチームもありました。
金メダルを目指していたので残念な結果にはなりましたが、また金メダル目指して頑張ろうと思います。